
PostgreSQL provides a built-in function named COUNT() that counts the number of records in a table. It retrieves the number of all records/rows, including duplicate/redundant records and null values. However, the DISTINCT clause can be used with the COUNT() function to count only unique/distinct values of a table.
This write-up is going to present a detailed guide on how to count unique values through practical examples. So, let’s get started!
How to Count Distinct/Unique Values in Postgres?
Use the DISTINCT Clause with the COUNT() function to count only the unique values:
COUNT(DISTINCT col_name);
Example: How to Count Distinct Values in Postgres?
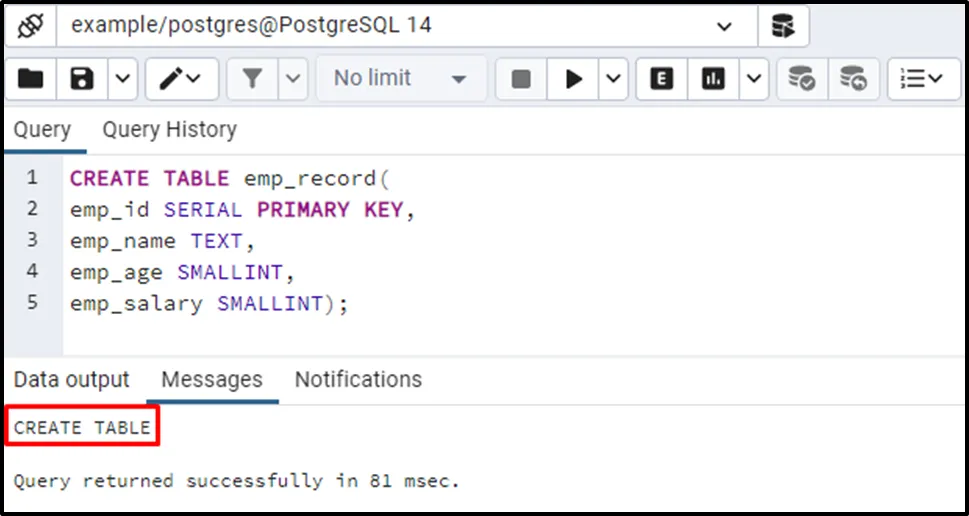
Firstly, we will create a sample table named emp_reocrd with four columns: emp_id, emp_name, emp_age, and emp_salary.
CREATE TABLE emp_record( emp_id SERIAL PRIMARY KEY, emp_name TEXT, emp_age SMALLINT, emp_salary SMALLINT);
We will insert multiple records into the emp_record table including some duplicates:
INSERT INTO emp_record(emp_name, emp_age, emp_salary)
VALUES ('JOHN', 26, 20000),
('JOE', 26, 25000),
('SETH', 29, 20000),
('JOHNSON', 34, 25000),
('JOHN', 26, 20000),
('MIKE', 22, 25000),
('JOE', 26, 25000),
('JOE', 26, 25000);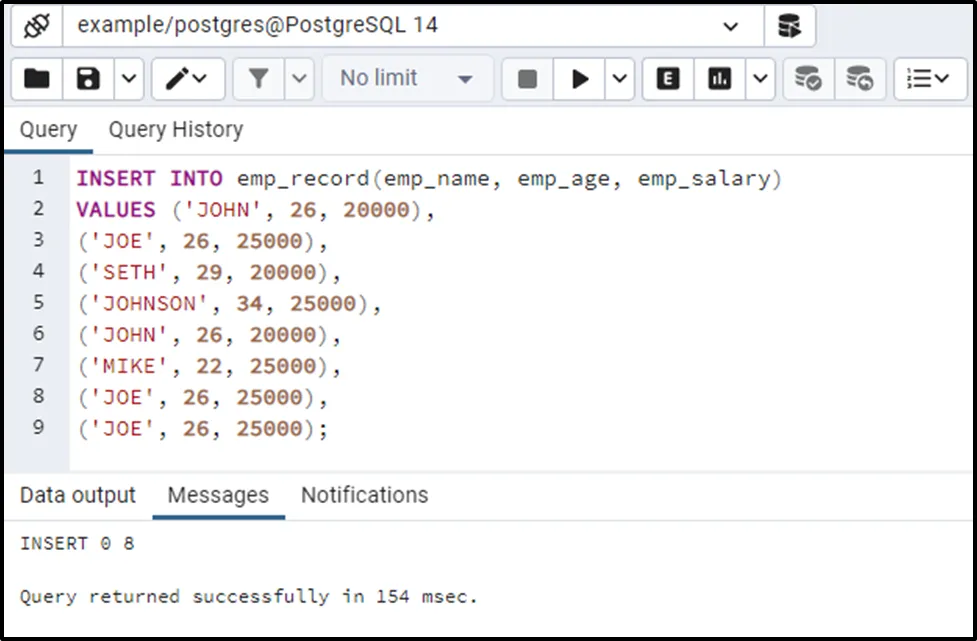
Let’s run the below command to see the table’s data:
SELECT * FROM emp_record;
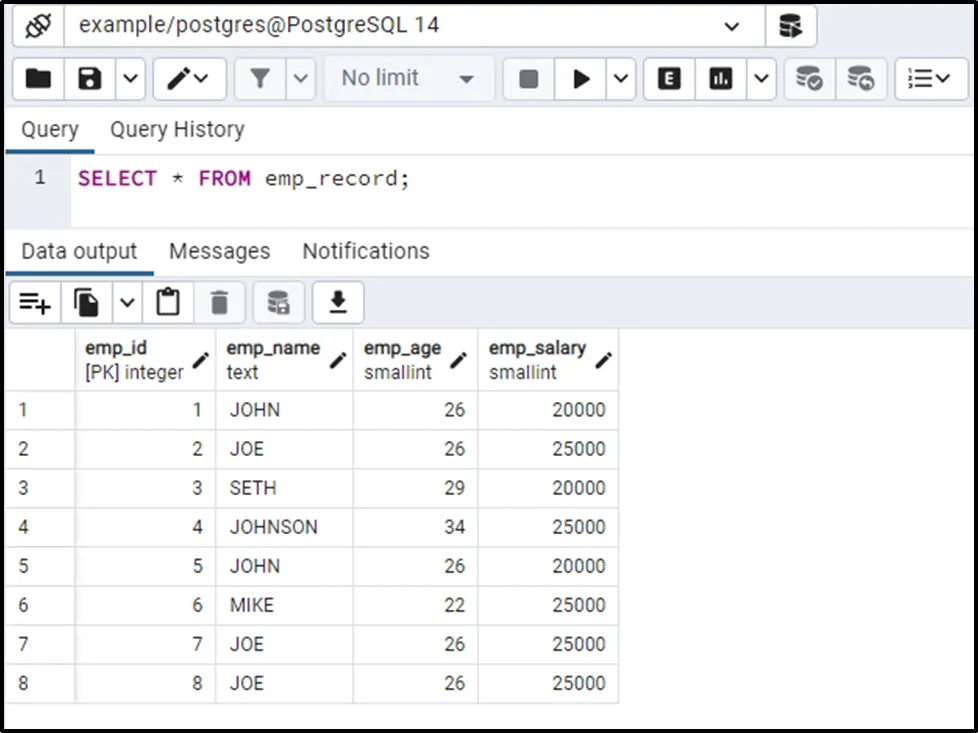
There are eight records in the emp_record table. Now use the COUNT() function to count the number of rows in the emp_record table:
SELECT COUNT(emp_name) FROM emp_record;
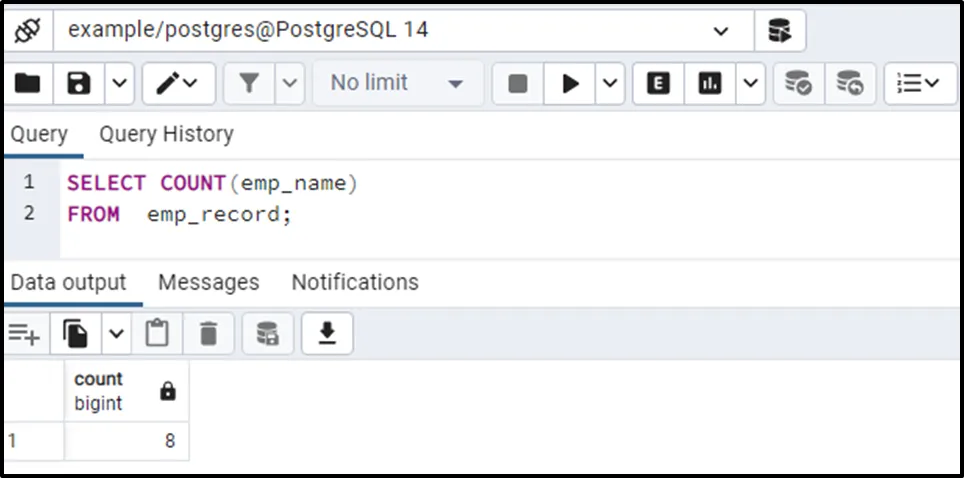
Output retrieves ‘8’, which proves that the COUNT() function counted each record, including duplicates. Run the below command to count only unique values from the emp_record table:
SELECT COUNT(DISTINCT emp_name) FROM emp_record;
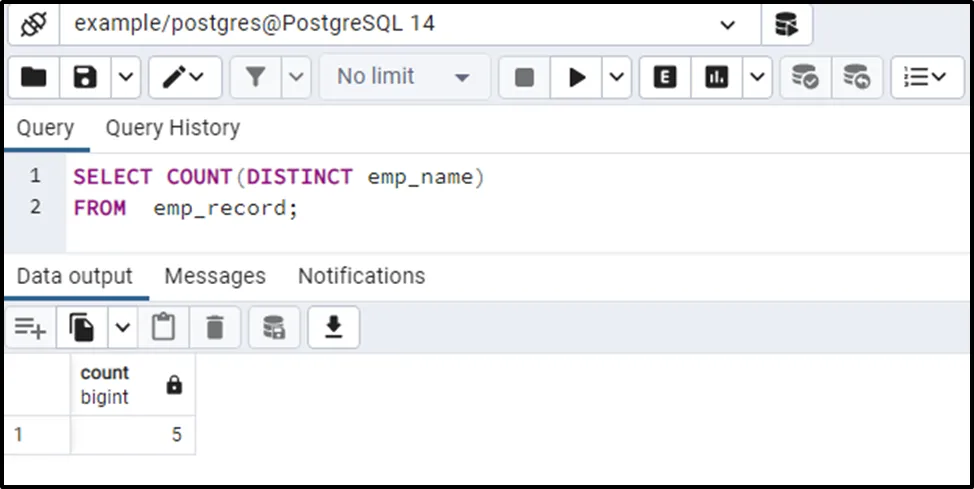
The COUNT() function returned '5' this time, proving that it only counts unique values.
This way, you can count the number of unique records; however, you can fetch the unique rows from the desired table using the DISTINCT clause as follows:
SELECT DISTINCT emp_name;
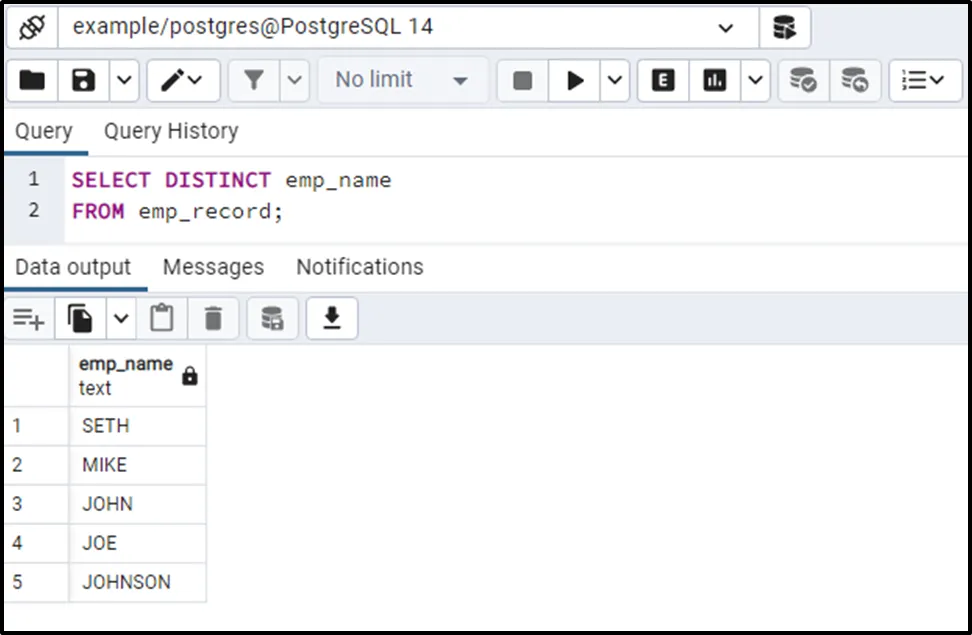
In the actual result set, JOHN occurs two times while JOE occurs three times. However, the DISTINCT clause skipped the duplicate names and retrieved only unique values.
Conclusion
In PostgreSQL, the DISTINCT clause can be used with the COUNT() function to count only unique/distinct values of a table. The simple COUNT() function retrieves all the rows/records, including duplicate values and null. To count only unique rows, you must specify a DISTINCT clause with the COUNT() function. Use the DISTINCT clause with the aid of the SELECT statement to get and describe the unique table records. Through practical examples, this post explained how to count the unique values from a table.

