
The UNIQUE constraint is a popularly used concept in PostgreSQL that helps us keep data precise, clean, and organized. It ensures the uniqueness/originality of the table records or values. By using the UNIQUE constraint on single or multiple columns, users can make sure that each value in those columns is unique and not repeated.
This post illustrates a comprehensive knowledge of adding or removing unique constraints from multiple columns.
How to Add a UNIQUE Constraint on Multiple Columns of a Postgres Table
Postgres enables its users to add/create a UNIQUE Constraint on multiple columns of a Postgres table while table creation. For this purpose, all you have to do is, follow the syntax provided below:
CREATE TABLE name_of_table( col_name_1 data_type, col_name_2 data_type, col_name_3 data_type, … col_name_N data_type, UNIQUE (col_name_1, col_name_2, …) );
Here, in the above-stated syntax:
- “col_name_1, col_name_2, …, col_name_N” are the table columns to be created.
- data_type represents any valid Postgres data type, such as INT, TEXT, VARCHAR, etc.
- UNIQUE is a keyword that is used to apply the UNIQUE constraint on the table’s columns.
- The “col_name_1, col_name_2, …” that are enclosed within a set of parentheses represent the columns on which the unique constraint will be applied.
Example: Applying Unique Constraint on Multiple Columns
Let’s create a “cp_employee” table and insert the unique constraint on a couple of its columns:
CREATE TABLE cp_employee( emp_id INT, emp_name TEXT, emp_email VARCHAR, UNIQUE (emp_id, emp_email) );
The following snippet indicates that the “cp_employee” table has been created with the desired columns:
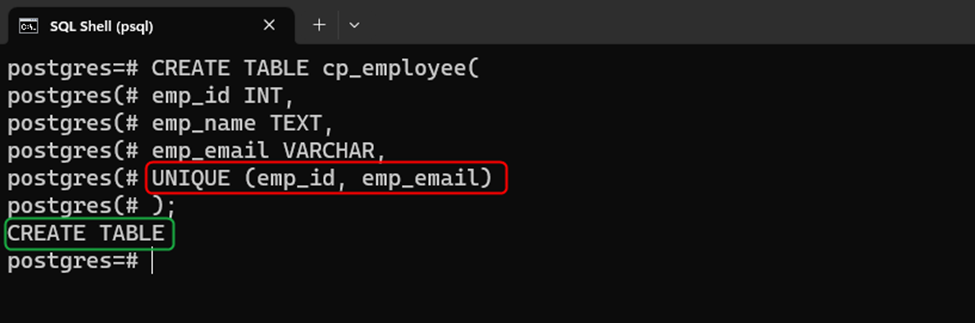
The UNIQUE constraint has been successfully applied to the “emp_id” and “emp_email” columns of the “cp_employee” table.
Let’s insert a couple of records to the newly created “cp_employee” table using the following command:
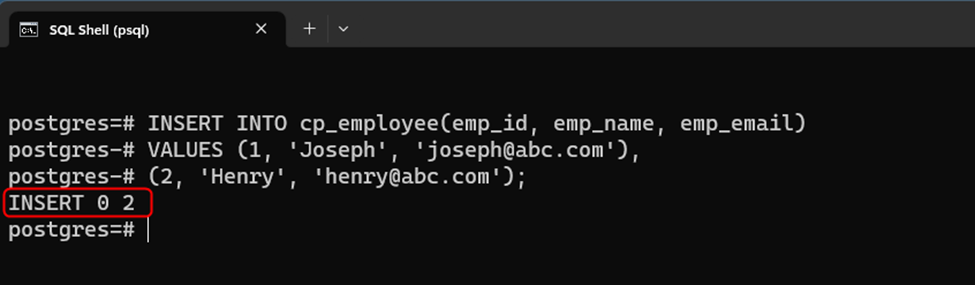
INSERT INTO cp_employee(emp_id, emp_name, emp_email) VALUES (1, 'Joseph', 'joseph@abc.com'), (2, 'Henry', 'henry@abc.com');
The output snippet shows that two records have been successfully inserted into the “cp_employee” table:
Now let’s try to insert a duplicate record into the “cp_employee” table and see how the UNIQUE constraint deals with that particular situation:
INSERT INTO cp_employee(emp_id, emp_name, emp_email) VALUES (1, 'Joseph', 'joseph@abc.com');
Inserting a duplicate record throws an error which indicates that the duplicate key value violates the unique constraint:

How to Add a UNIQUE Constraint on Multiple Columns of an Existing Postgres Table?
Use the below-provided syntax to add/set a UNIQUE constraint on various columns of an existing PostgreSQL table:
ALTER TABLE name_of_table ADD CONSTRAINT constraint_name UNIQUE (col_name_1, col_name_2, …);
Here, in the above-stated syntax:
- “name_of_table” indicates an existing table that needs to be altered.
- “ADD CONSTRAINT” is a clause that applies uniqueness to the desired table columns.
- The “col_name_1, col_name_2, …” that are enclosed within a set of parentheses represent the columns on which the unique constraint will be applied.
Example: Applying UNIQUE Constraint on Existing Table
We have an already existing table named “emp_info” having the following structure:
\d emp_info;
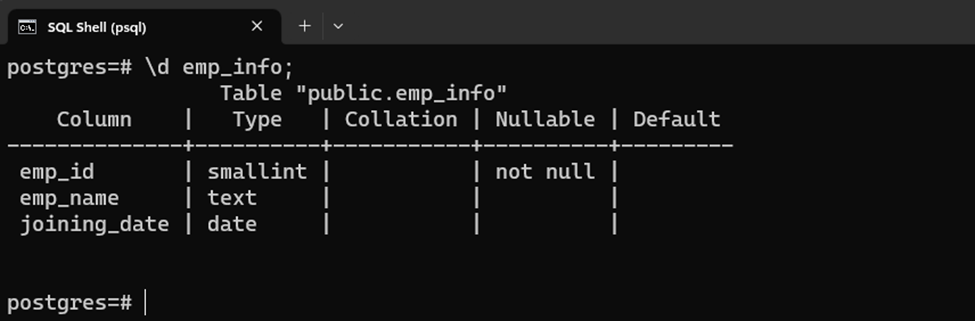
Suppose we have to apply a UNIQUE constraint on the “emp_id” and “emp_name” columns. For that purpose, we will execute the ALTER TABLE command with the UNIQUE constraint as follows:
ALTER TABLE emp_info ADD CONSTRAINT unique_constraints UNIQUE (emp_id, emp_name);
The selected table has been successfully altered:
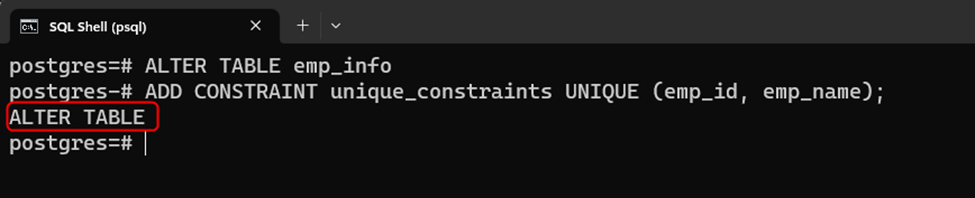
Users can confirm the table alteration by executing the below-provided command:
\d emp_info;
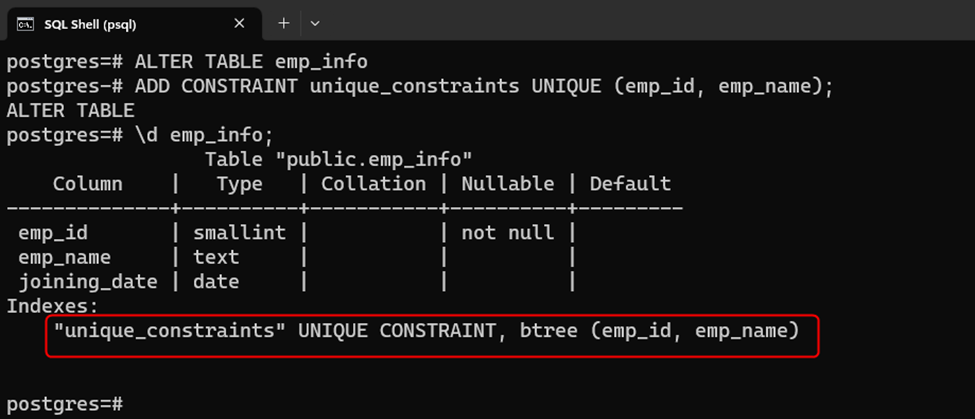
From the output, it is clear that the UNIQUE CONSTRAINT has been successfully applied to the selected columns.
How to Remove/DROP a UNIQUE Constraint From Multiple Columns of a PostgreSQL Table
PostgreSQL uses the ALTER TABLE command with the DROP CONSTRAINT clause to remove/drop the uniqueness from single or multiple columns:
ALTER TABLE name_of_table DROP CONSTRAINT name_of_constraint;
Replace the “name_of_table” with the desired table name and “name_of_constraint” with the constraint names that need to be removed.
Example: Removing Unique Constraint From Multiple Columns
Let’s use the DROP CONSTRAINT clause with the selected constraint name to remove it from the “cp_employee” table:
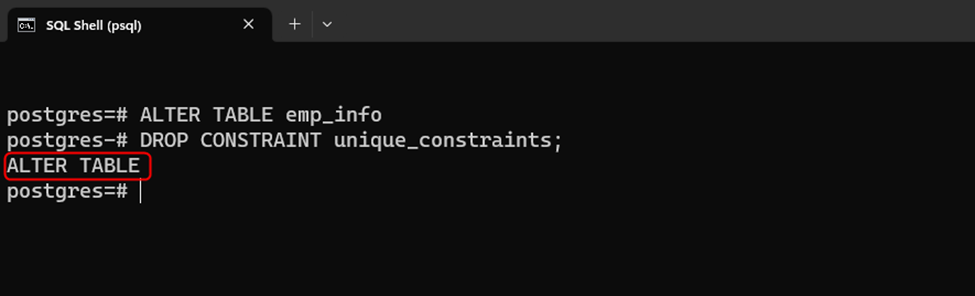
ALTER TABLE name_of_table DROP CONSTRAINT unique_constraints;
The unique constraint has been successfully removed from the multiple columns:
Execute the “\d” command with the table name to confirm the constraint deletion:
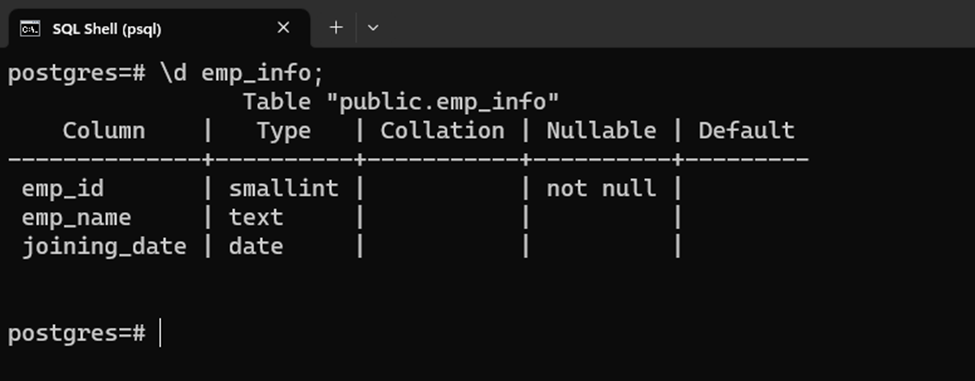
\d emp_info;
The output indicates that the unique constraint has been successfully removed from the selected columns:
That’s all about adding or removing unique constraints on multiple columns of a PostgreSQL table.
Conclusion
In PostgreSQL, the “UNIQUE” keyword is used with the CREATE TABLE or ALTER TABLE commands to add a unique constraint on single/multiple columns of a new or an already existing Postgres table. Moreover, PostgreSQL uses the ALTER TABLE command with the DROP CONSTRAINT clause to remove the uniqueness from single or multiple columns of the selected table. This post has illustrated how to add or remove UNIQUE constraints from multiple columns of a particular table.


