
PostgreSQL is a versatile open-source relational database management system (RDBMS) that supports built-in as well as user-defined data types. These data types help us store, retrieve, and manipulate the data efficiently and effortlessly. However, selecting an appropriate/right data type is crucial. Are you finding it difficult to understand when and where to use which data type? No need to worry, because in this guide, we will solve all your issues related to data types, and that too with examples.
Outline
This blog will walk you through the following PostgreSQL data types using appropriate examples:
- Numeric Data Types in PostgreSQL
- SERIAL Data Types
- Character Data Types
- Temporal Data Types
- Boolean Data Type
- Array Data Type
- JSON Data Type
- UUID Data Type
Let’s begin with the Numeric data types.
Numeric Data Types in PostgreSQL
PostgreSQL offers several built-in data types to work with the numeric data, such as floating-point, integer, numeric, and serial. All of them differ in range and serve unique purposes. We will understand each of these data types using suitable examples.
Integer Data Types
SMALLINT, INTEGER, and BIGINT are the frequently used 2-byte, 4-byte, and 8-byte signed integer data types in PostgreSQL. The below table shows the storage size, minimum range, and maximum range of each integer data type:

The following example creates a table with different integer data types:
CREATE TABLE student_info( student_Id INT PRIMARY KEY, student_Age SMALLINT, student_Name TEXT, );
The desired “student_info” table is successfully created with the “student_Id”, “student_Age”, and “student_Name” columns:

Floating-point Data Types
Postgres offers a couple of floating point data types to deal with the fractional values. These types include “DOUBLE PRECISION” and “FLOAT”. The “FLOAT” data type consumes 4 bytes while “DOUBLE PRECISION” consumes 8 bytes of storage. The following code uses the DOUBLE PRECISION data type to store the student marks:
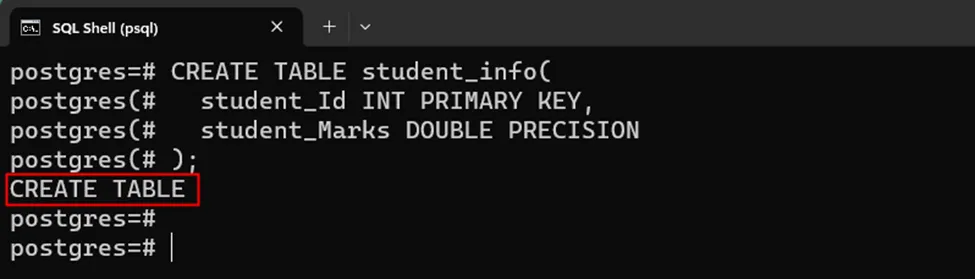
CREATE TABLE student_info( student_Id INT PRIMARY KEY, student_Marks DOUBLE PRECISION, );
NUMERIC Data Type
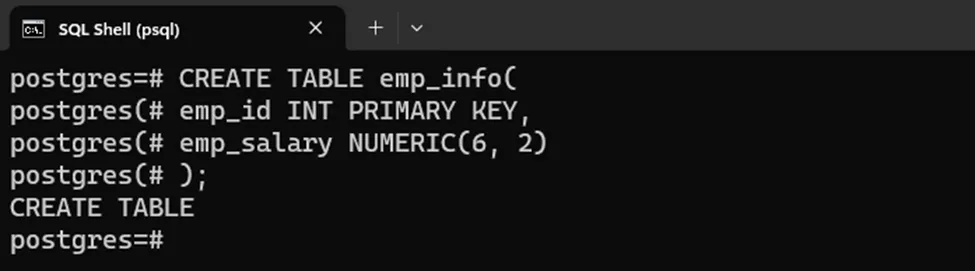
NUMERIC data type allows us to store exact figures in the database. It is capable of storing a number with several digits. The NUMERIC type can accept two options: “precision” and “scale”. Where the precision indicates the total digits to store and the scale refers to the total digits in the fractional part. The following query creates a table named “emp_info” with two columns: “emp_Id” and “emp_salary”:
CREATE TABLE emp_info( emp_Id INT PRIMARY KEY, emp_salary NUMERIC(6, 2), );
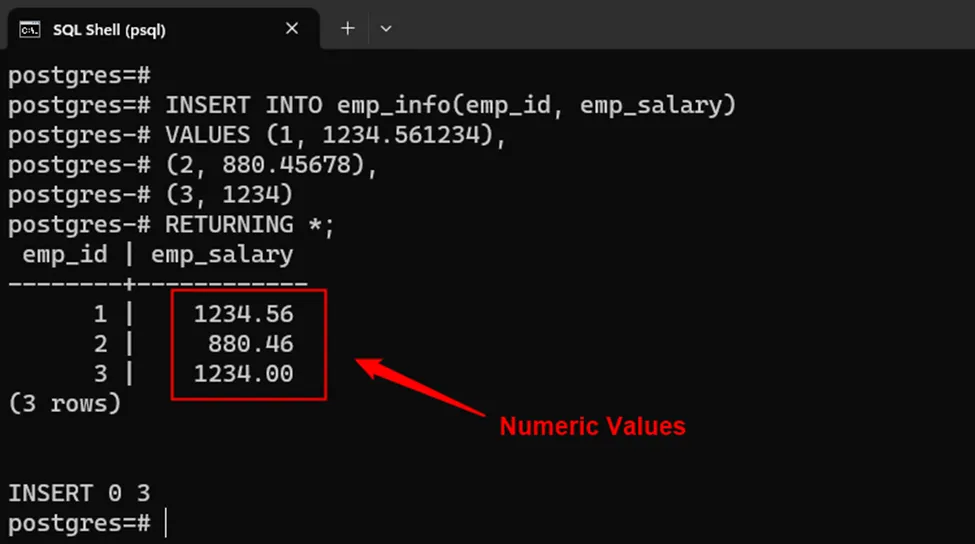
The emp_salary column will store a numeric value of 6 digits. Out of which the fractional part can have at max 2 digits. Now add/insert some new records into the emp_info table to get a better understanding:
INSERT INTO emp_info(emp_id, emp_salary) VALUES (1, 1234.561234), (2, 880.45678), (3, 1234) RETURNING *;
From the output, you can observe that three values have been successfully inserted according to the specified scale and precision:
SERIAL Data Types
Postgres offers three SERIAL types that help us create auto-increment columns. These data types are “BIGSERIAL”, “SMALLSERIAL”, and “SERIAL”. The storage range of these sudo types is different, as illustrated in the following table:
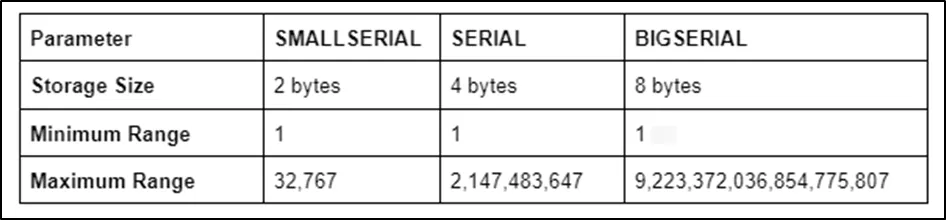
The main factor that differentiates the mentioned data types from each other is the range of numbers they can save/store. The BIGSERIAL data type can keep the largest range of values, which is followed by the SERIAL data type, and finally, the SMALLSERIAL type which stores the least range of values.
For example, the following query creates a table with the SERIAL and SMALLSERIAL pseudotypes:
CREATE TABLE emp_info( emp_Id SERIAL PRIMARY KEY, emp_name TEXT );
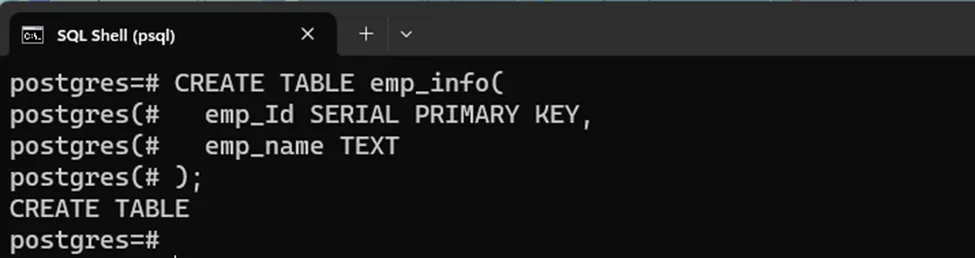
Let’s insert some records into the newly created table to understand how the SERIAL types work in PostgreSQL:
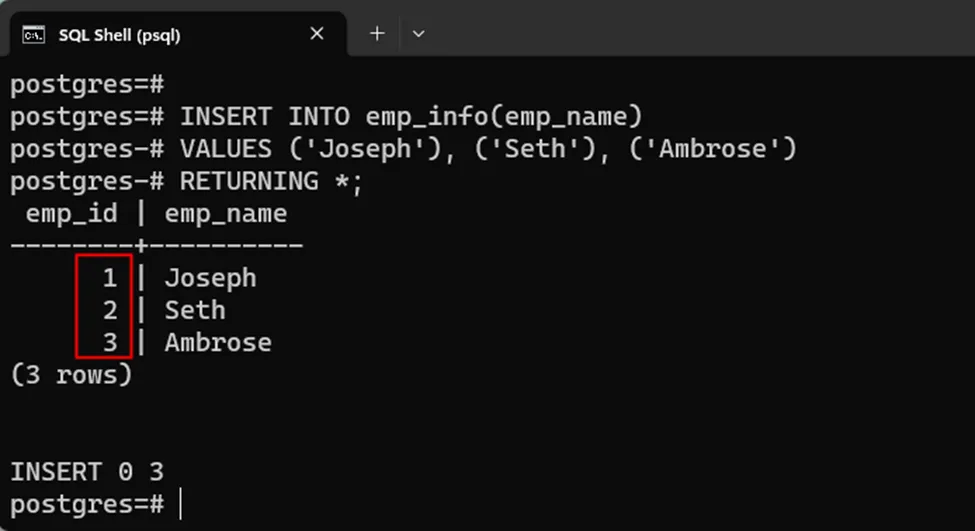
INSERT INTO emp_info(emp_name)
VALUES('Joseph'), ('John'), ('Seth');The output shows that three auto-incrementing IDs have been successfully added to the emp_info table:
Character Data Types
Postgres supports three character types: CHAR, TEXT, and VARCHAR. You can employ any of the mentioned types to store the textual data. The following table illustrates these data types with respect to different parameters:

Note: In the fixed-length data types, exceeding the specified limit will result in a “value too long for type dataType” error.
The below code block creates a table with four columns: “emp_Id”, “emp_name”, “gender”, and “address”:
CREATE TABLE emp_details( emp_Id SERIAL PRIMARY KEY, emp_name TEXT, gender CHAR, address VARCHAR );
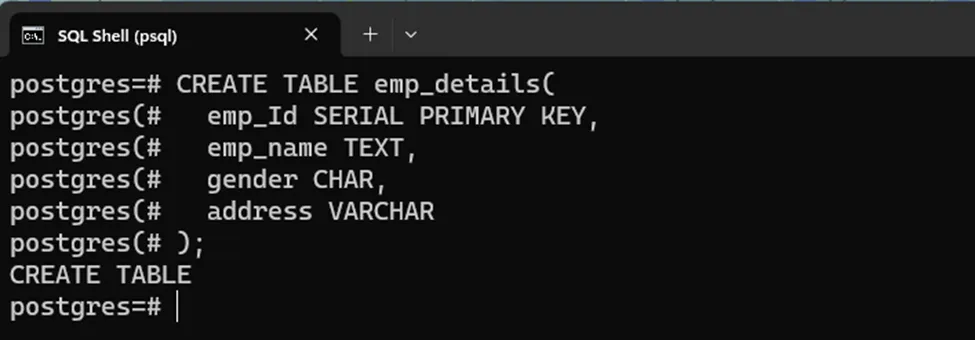
A table with the desired columns and data types is created successfully. Now you can insert data into this table and perform any data operation on it according to your preferences.
Temporal Data Types
In databases, date and time play a crucial role. Therefore, Postgres offers several temporal data types to work with date and time data. The commonly used temporal data types include time, date, interval, and timestamp. The DATE, TIME, and TIMESTAMP data types store the data in the “YYYY-MM-DD”, “HH:MI:SS”, and the “YYYY-MM-DD HH:MI:SS” formats, respectively. Let’s create a table with these data types to store the temporal data:
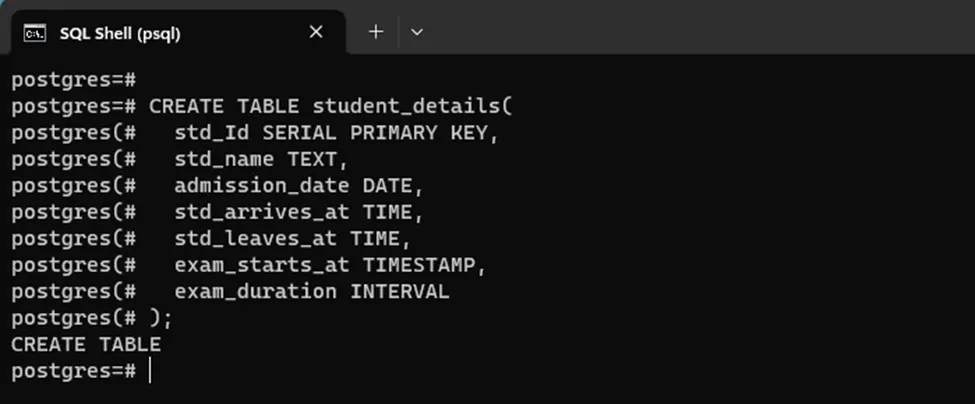
CREATE TABLE student_details( std_Id SERIAL PRIMARY KEY, std_name TEXT, admission_date DATE, std_arrives_at TIME, std_leaves_at TIME, exam_starts_at TIMESTAMP, exam_duration INTERVAL );
The student_details table with seven columns is created successfully:
Let’s insert a record into this newly created table to get a better insight into temporal data types:
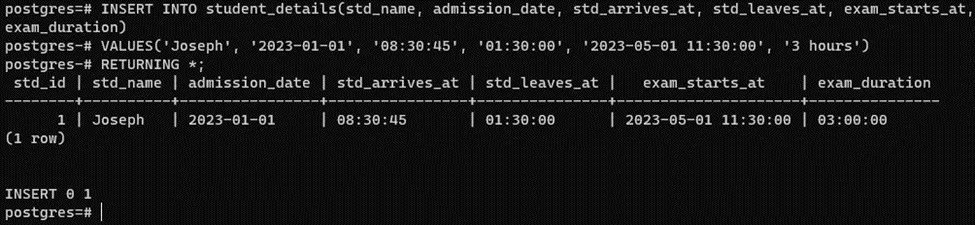
INSERT INTO student_details(std_name, admission_date, std_arrives_at, std_leaves_at, exam_starts_at, exam_duration)
VALUES('Joseph', '2023-01-01', '08:30:45', '01:30:00', '2023-05-01 11:30:00', '3 hours')
RETURNING *;Here is what you will experience on successful execution of the stated query:
Boolean Data Type
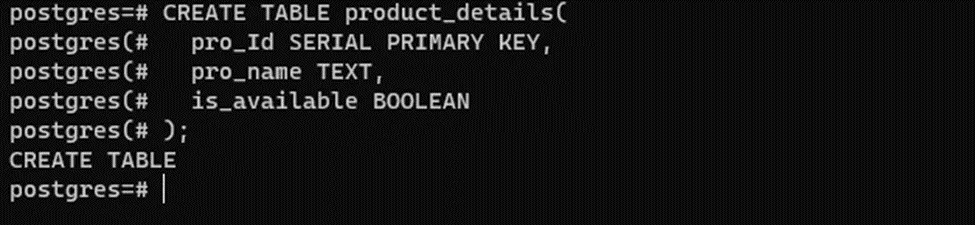
The Boolean data type is used in scenarios where we have only two possible outcomes, such as “Yes/No”, “True/False”, “0/1”, etc. For example, the following code will create a table “product_details” with three columns: pro_Id, pro_name, and is_availble. The is_availble is a boolean-type column that shows the availability of a product (it will be either true or false):
CREATE TABLE product_details( pro_Id SERIAL PRIMARY KEY, pro_name TEXT, is_available BOOLEAN );
The table with the desired boolean column is created successfully:
We insert the data of two products and their availability:
INSERT INTO product_details(pro_name, is_available)
VALUES('Laptop', 'Yes'),
('Laptop Charger', 'No')
RETURNING *;The output shows that the product “Laptop” is available in the stock while “Laptop Charger” isn’t:

Array Data Type
If you want to store several values of the same type, then use the ARRAY data type. For example, a person can have multiple emails, multiple bank accounts, etc. In that cases, you can use the Postgres’ Array Data type:
CREATE TABLE std_info ( std_id SERIAL PRIMARY KEY, std_name VARCHAR(50), std_emails TEXT[] NOT NULL );
We create a text array for the std_emails:

Up next, we execute the insert query to insert the data of two students: “Joseph” and “John”:
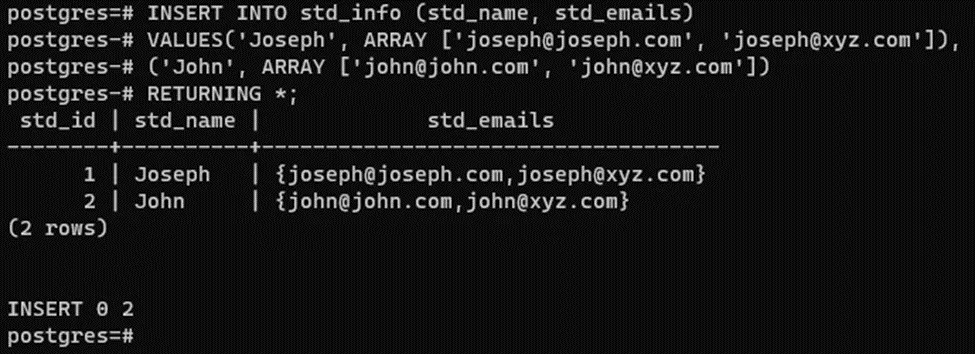
INSERT INTO std_info (std_name, std_emails)
VALUES('Joseph', ARRAY ['joseph@joseph.com', 'joseph@xyz.com']),
('John', ARRAY ['john@john.com', 'john@xyz.com'])
RETURNING *;The output shows that the emails are inserted/stored in the text array “std_emails”:
JSON Data Type
The JSON data type allows us to insert the data in the form of key-value pairs. It is used when we have to keep/store complex data structures that can be serialized and deserialized, effortlessly.
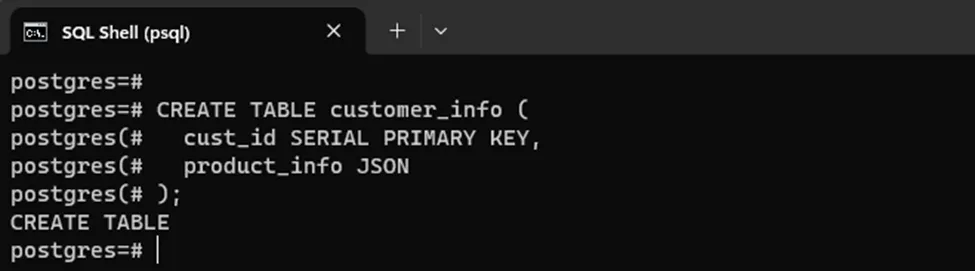
The following code block creates a table “customer_info” with two columns: cust_id and product_info.
CREATE TABLE customer_info ( cust_id SERIAL PRIMARY KEY, product_info JSON );
Here the product_info is a JSON-type column:
Let’s insert a couple of JSON records to see how we can store key-value pairs in Postgres:
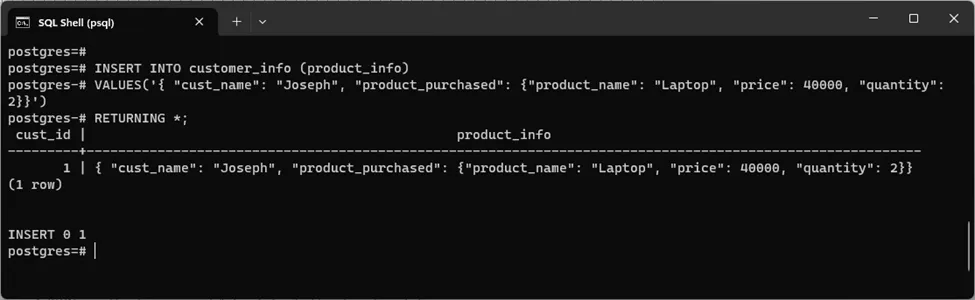
INSERT INTO customer_info (product_info)
VALUES('{ "cust_name": "Joseph", "product_purchased": {"product_name": "Laptop", "price": 40000, "quantity": 2}}')
RETURNING *;A JSON record has been successfully inserted and retrieved, as shown below:
UUID Data Type
Postgres supports some special data types that are not available in other DBMSs. “UUID” or “Universal unique identifier” is one of them that stores 128-bit unique identifier values. To use this data type first, you need to create its extension as it doesn’t come by default:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";

Now create a customer_details table with a UUID-type column:
CREATE TABLE customer_details ( cust_id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), name TEXT );

Let’s insert the customer name into the name column of the customer_details table:
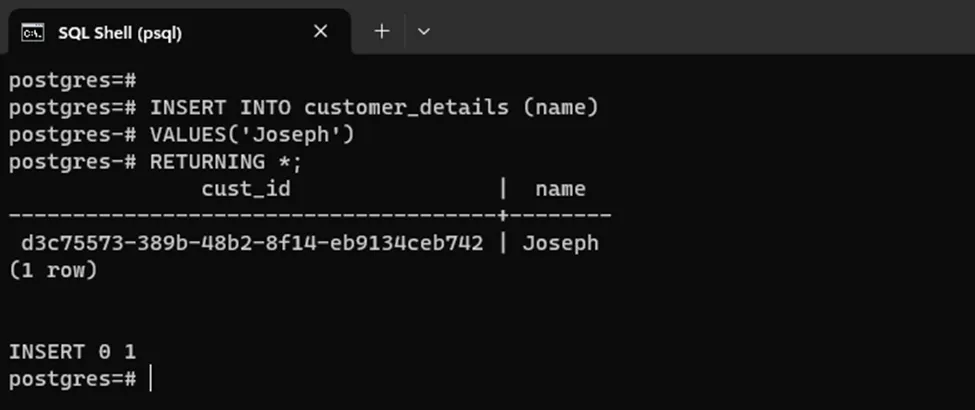
INSERT INTO customer_details (name)
VALUES('Joseph')
RETURNING *;An auto-generated unique identifier value is added to the UUID column:
Important: Other than these built-in data types, you can also create user-defined data types using the CREATE DOMAIN and CREATE TYPE statements.
Conclusion
PostgreSQL provides a wide range of data types, such as textual, numeric, and temporal, for efficient data storage and manipulation. The choice of any data type is aligned with your specific needs and preferences. However, choosing the right data type is crucial for better memory management, and maintaining data accurately and efficiently. Having a profound knowledge of data types enables a user to make the right decisions at the right moment. This way you can store and manipulate your data securely and effectively.
In this guide, we have exercised different Postgres data types along with appropriate examples.

