
Deleting duplicate rows from a table is a little bit tricky. Finding and deleting duplicate rows is pretty easy if the table has a limited number of records. However, if the table has enormous data, then finding and deleting the duplicates can be challenging.
PostgreSQL provides multiple ways to find and delete duplicate rows in PostgreSQL. This post discusses the below-listed methods to find and delete duplicate rows in PostgreSQL:
● How to Find Duplicate Rows in PostgreSQL?
● How to Delete Duplicates in Postgres Using a DELETE USING Statement?
● How to Delete Duplicates Using Subquery?
● How to Delete Duplicates Using Immediate Tables in Postgres?
To illustrate this concept more clearly, let's create a sample table.
Creating Sample Table
Let’s create a table named programming_languages and insert some duplicate rows in it:
CREATE TABLE programming_languages( id INT, language VARCHAR(100) NOT NULL );
The programming_languages table has been created successfully. Let’s insert some data into it:
INSERT INTO programming_languages(id, language) values(1, 'C'), (2, 'C++'), (3, 'C'), (4, 'Java'), (5, 'Python'), (6, 'C++'), (7, 'C++'), (8, 'R'), (9, 'Java'), (10, 'JavaScript');
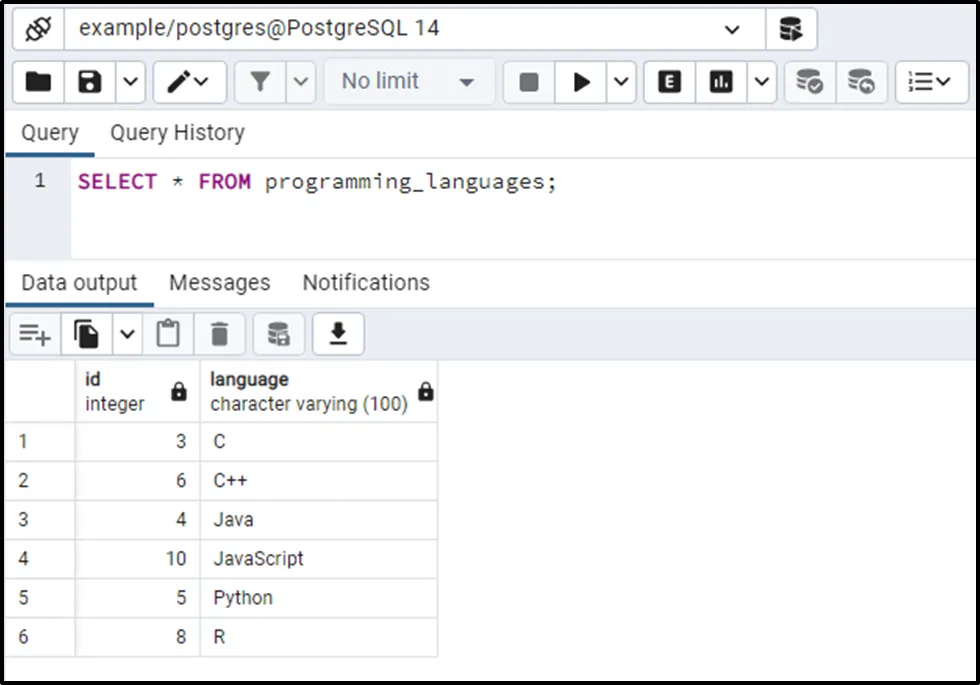
Let’s run the SELECT command to see the newly inserted data from the programming_languages table:
SELECT * FROM programming_languages;
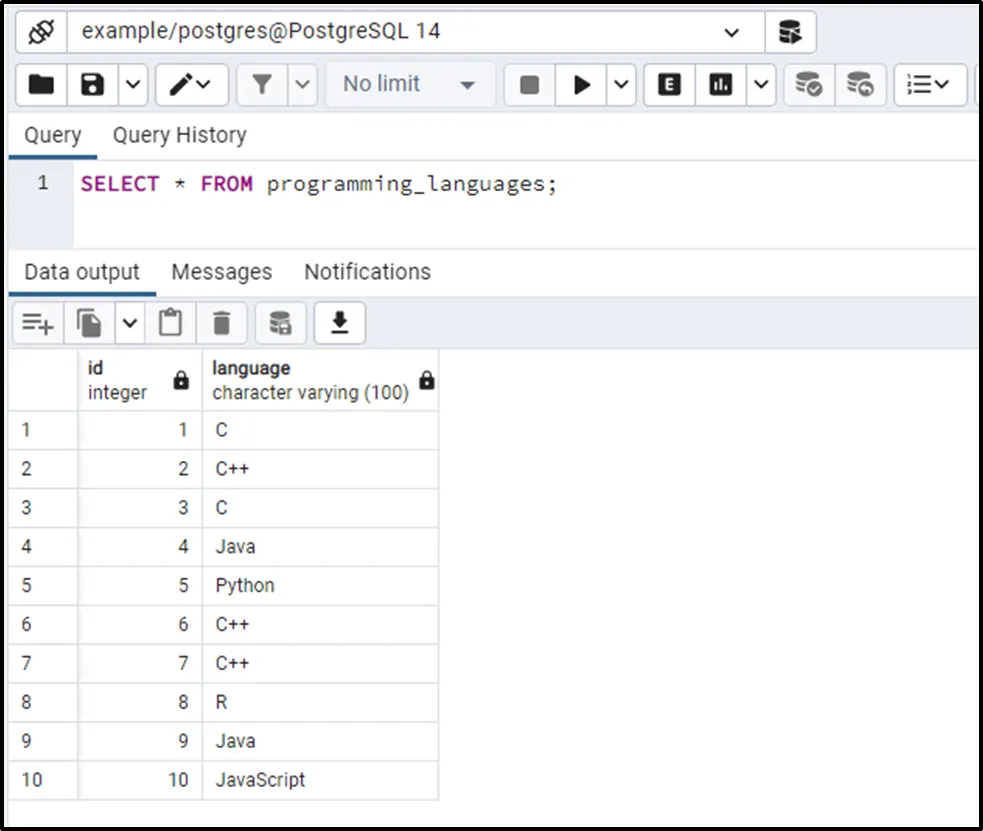
The output shows that the programming_languages table contains some duplicated records. Since the programming_languages table has limited records, so we can calculate the duplicates easily. However, counting the duplication of rows in large tables is challenging.
How to Find Duplicate Rows in PostgreSQL?
Use the COUNT() function to find the duplicate rows from a table. Execute the below code to find the duplicate rows in the programming_languages table:
SELECT language, COUNT(language) FROM programming_languages GROUP BY language HAVING COUNT(language)> 1;
From the programming_languages table, the SELECT statement will fetch the language column and number of occurrences of a language.
The GROUP BY clause will split the result set into groups based on the language column.
The HAVING clause will pick only those languages that occur more than once:
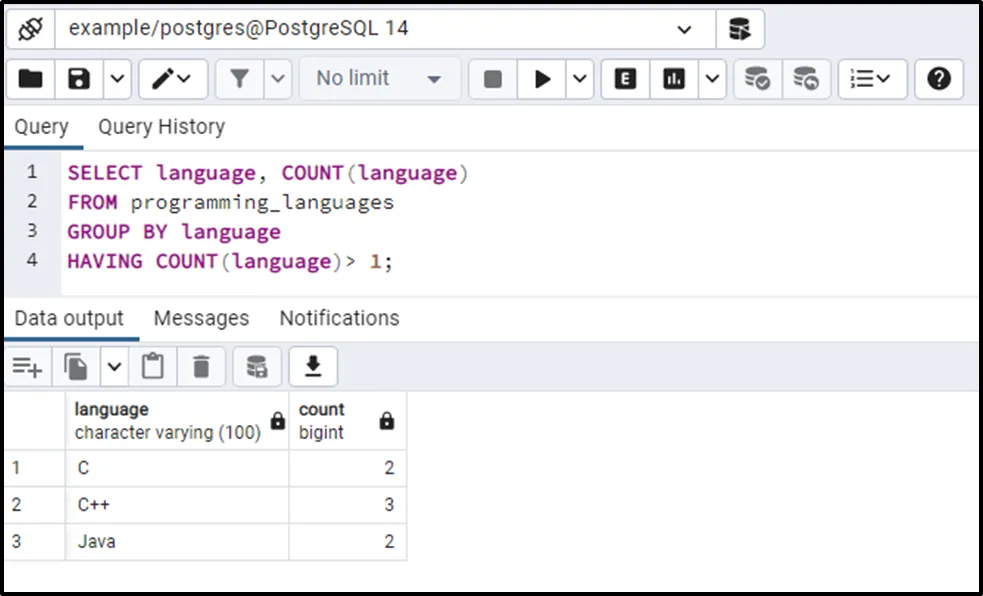
This way, you can find the duplicate rows using the COUNT() function.
How to Delete Duplicates in Postgres Using a DELETE USING Statement?
To delete duplicate rows from a table, use the below statement:
DELETE FROM programming_languages dup_lang USING programming_languages dist_lang WHERE dup_lang.id < dist_lang.id AND dup_lang.language = dist_lang.language;
The above snippet performs the following tasks:
- Joined the programming_languages table to itself.
- Checked if two records (dup_lan.id < dist_lang.id) have the same value in the language column.
- If yes, then the duplicated record will be deleted.
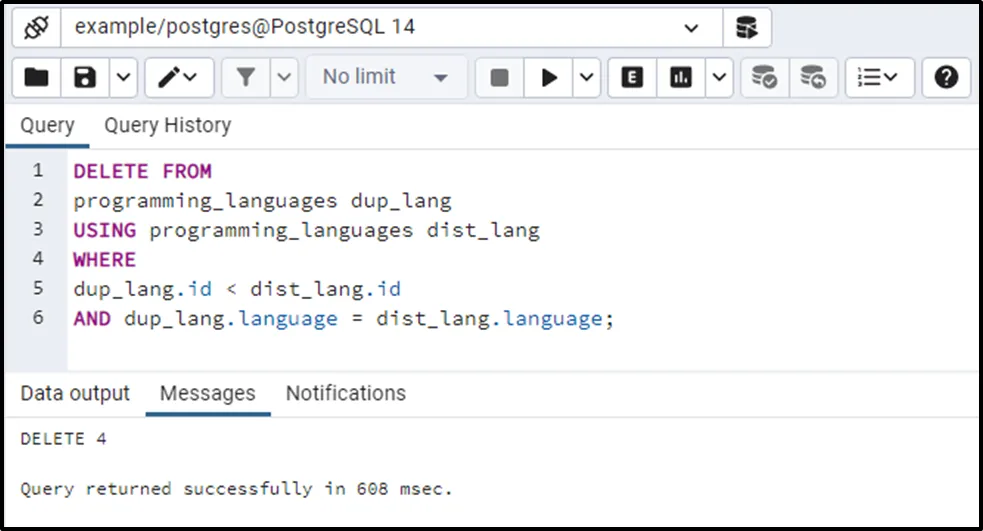
The output shows that four rows(duplicate) have been deleted from the programming_languages table. Let’s confirm the rows(duplicate) deletion using the below command:
SELECT * FROM programming_languages;
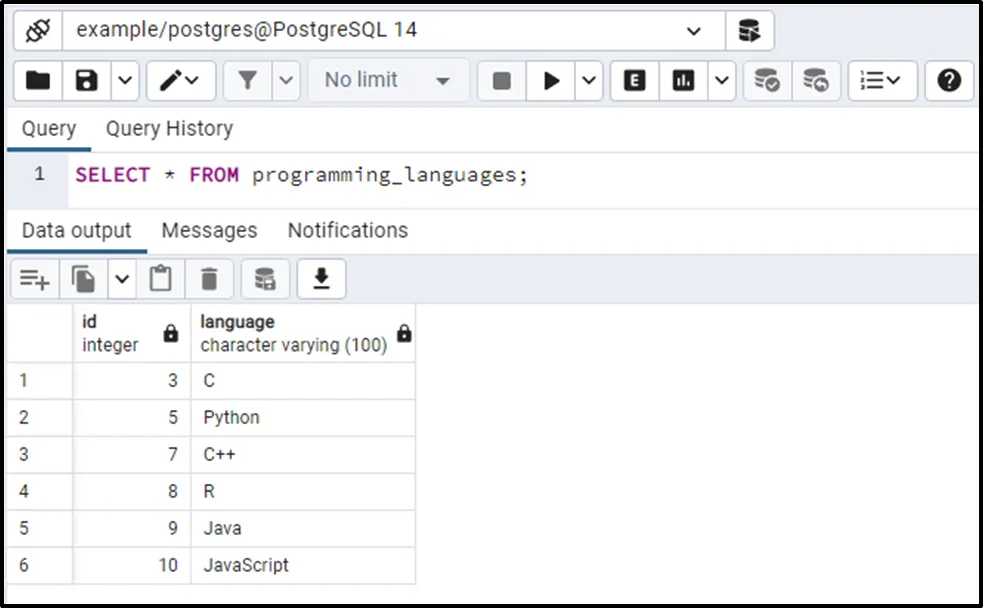
The output shows that the programming_languages table contains only unique languages. It proves that the duplicated rows have been deleted successfully.
As you can see from the output, the DELETE USING query deletes the languages with low IDs and retains the languages with high IDs. If you want the languages with high ids instead of low ids then use the “>” sign in the WHERE clause:
DELETE FROM programming_languages dup_lang USING programming_languages dist_lang WHERE dup_lang.id > dist_lang.id AND dup_lang.language = dist_lang.language;
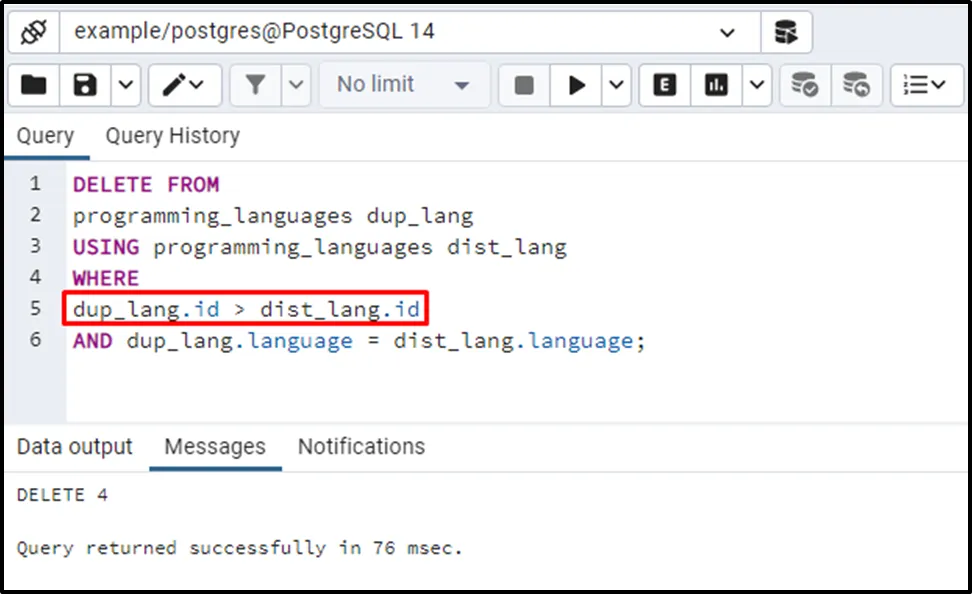
Let’s confirm the deletion of the rows using the below command:
SELECT * FROM programming_languages;
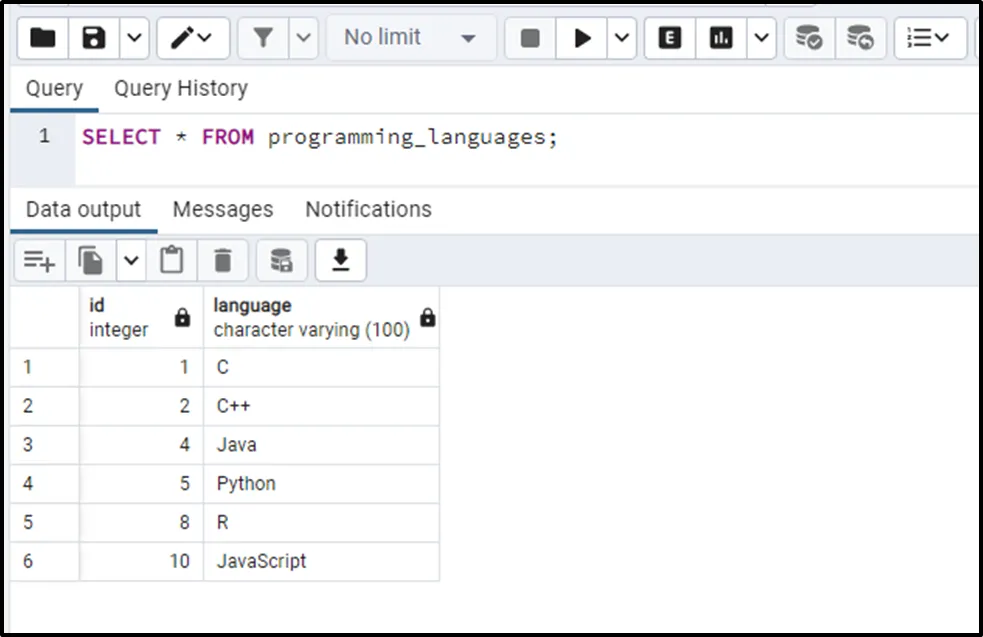
This time the DELETE USING statement deletes the duplicates with high ids.
How to Delete Duplicate Rows Using Subquery in PostgreSQL?
Run the following query for deleting duplicate rows from a table by employing a subquery:
DELETE FROM programming_languages WHERE id IN (SELECT id FROM (SELECT id, ROW_NUMBER() OVER(PARTITION BY language ORDER BY id ASC) AS row_num FROM programming_languages) lang WHERE lang.row_num > 1 );
The above-given query will perform the following functionalities:
- Use a subquery in the WHERE clause.
- Within the subquery, each row of a result set will have a unique integer value assigned by the ROW_NUMBER() function.
- Subquery will return the duplicate records except for the first row.
- The DELETE FROM query will delete the duplicates that are returned by the subquery.
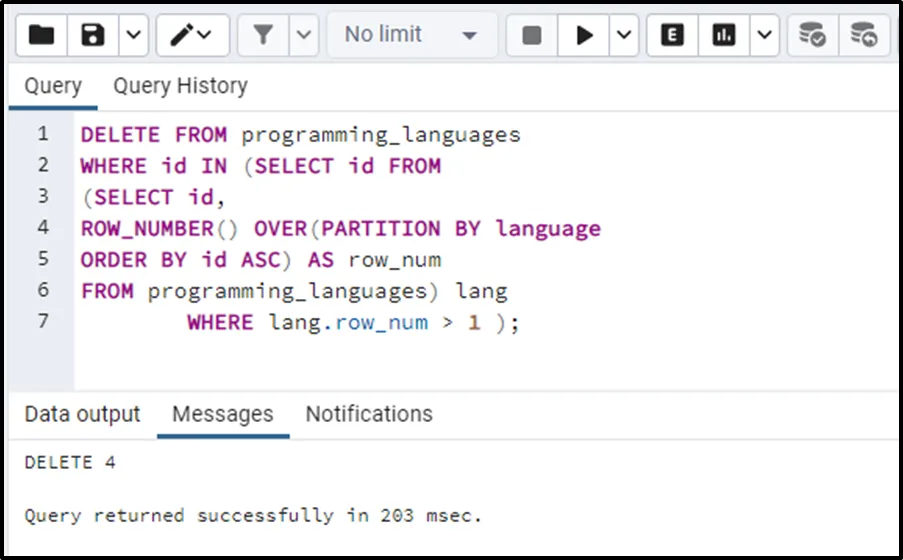
The above query will delete the duplicates with low ids. Let’s run the SELECT statement to confirm the working of the above query:
SELECT * FROM programming_languages;
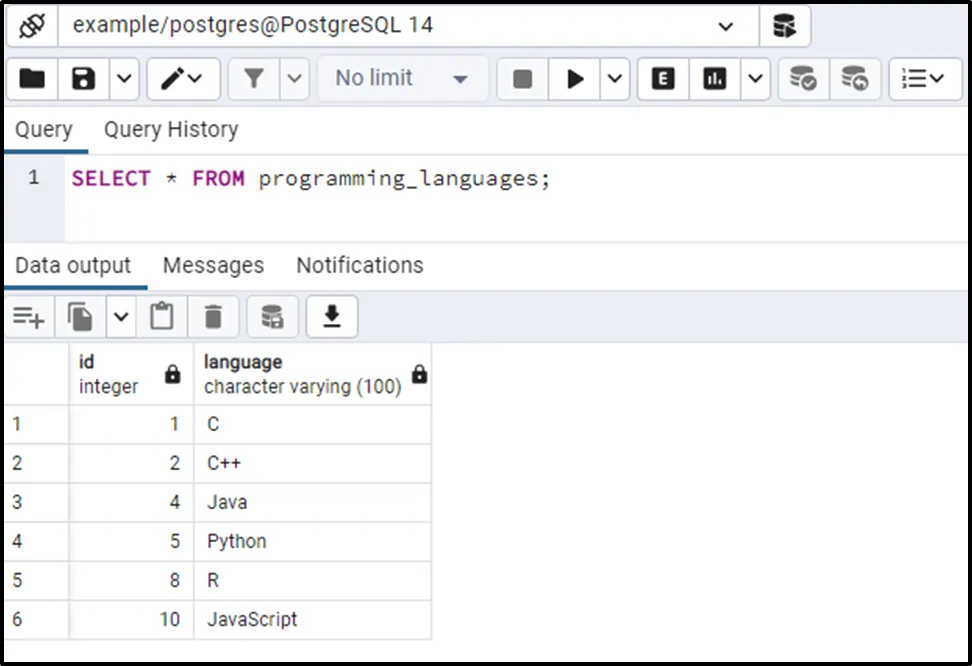
As you can see from the output, the result set does not contain any duplicate records. To retain records with the greatest ID, specify the DESC in the ORDER BY clause.
How to Delete Duplicate Rows Using Immediate Tables in PostgreSQL?
In Postgres, you can use the immediate tables to delete duplicate rows. For better understanding, follow the below-listed stepwise procedure:
Step 1: Create a Table
Firstly, you have to create a table having the same structure as the targeted table (programming_languages). To do this, run the below command:
CREATE TABLE temp_table (LIKE programming_languages);
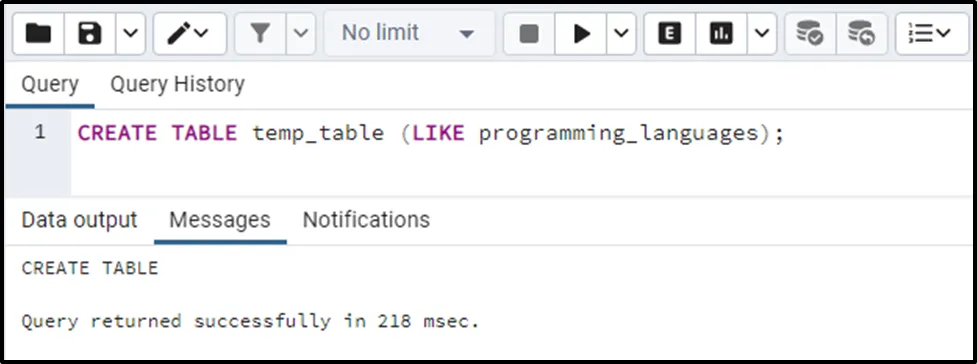
Let’s check the newly created table’s structure using the SELECT command:
SELECT * FROM temp_table;
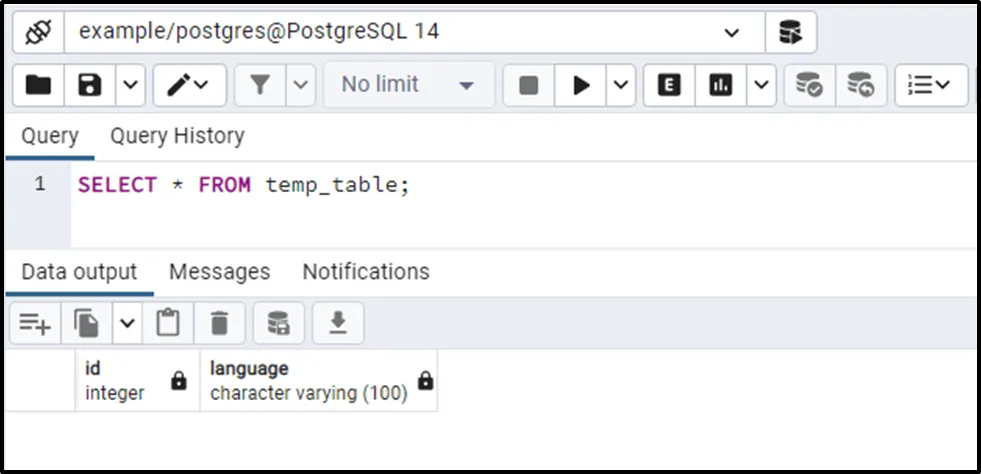
The output verifies that the temp_table has the same structure as the programming_languages table.
Step 2: Insert Distinct Records to the temp_table
Let’s insert the distinct rows from the programming_languages(source) table to the newly created table using the following command:
INSERT INTO temp_table(id, language) SELECT DISTINCT ON (language) id, language FROM programming_languages;
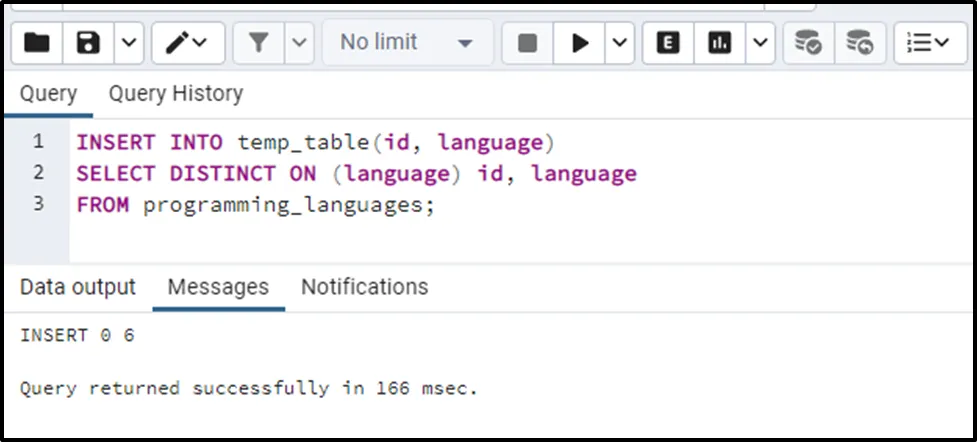
Let’s verify the table’s records using the below-given query:
SELECT * FROM temp_table;
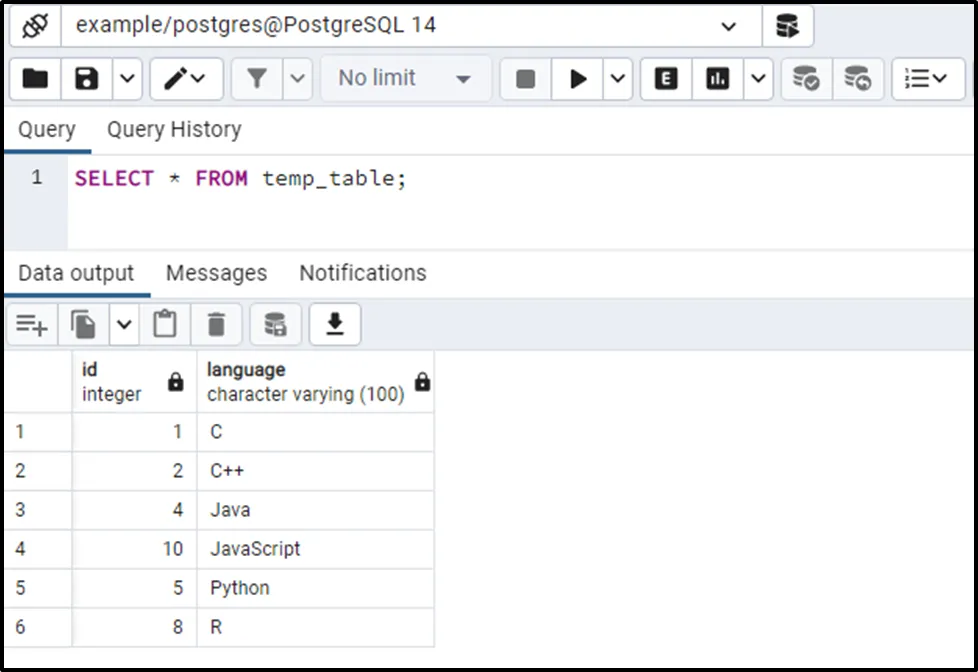
The output shows that the temp_table has only unique records.
Step 3: Drop the Source Table
Use the DROP TABLE command to drop the source table (i.e. programming_languages):
DROP TABLE programming_languages;
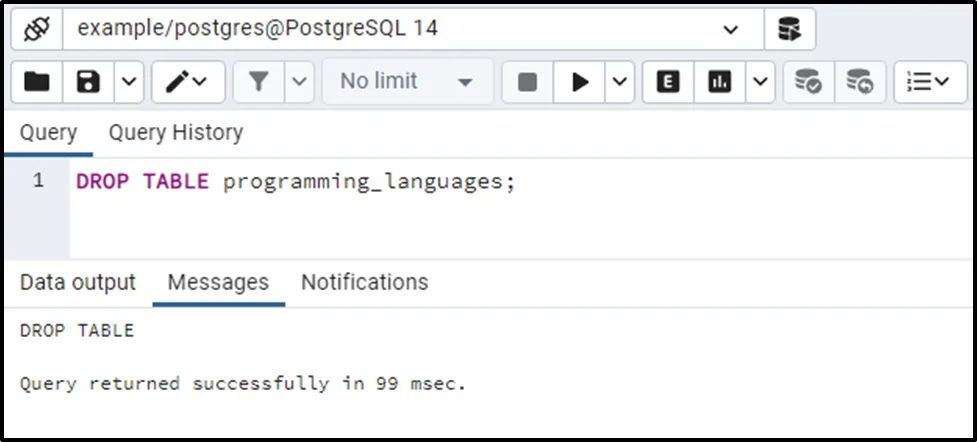
The source table has been dropped successfully.
Step 4: Rename the temp_table to the programming_languages
Utilize the ALTER TABLE statement for renaming the temp_table to the programming_languages:
ALTER TABLE temp_table RENAME TO programming_languages;
Let’s run the above statement to verify weather the temp_table has been renamed to programming_languages or not:
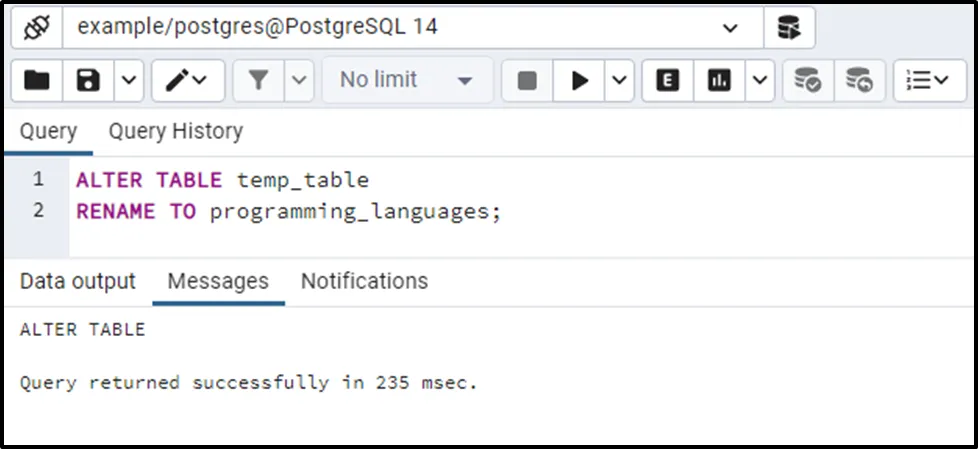
The temp_table has been altered successfully. Here are the details of programming_languages table:
SELECT * FROM programming_languages;
This way you can find and delete the duplicate rows from a table in PostgreSQL.
Conclusion
PostgreSQL offers multiple ways to find and delete duplicate rows. For finding the duplicates, we can utilize the Postgres COUNT() function. While to remove duplicate rows, we can use the “DELETE USING” Statement, subquery, or Postgres immediate Table. This write-up explained each method with practical examples.

