
In PostgreSQL, partitions play an important role in categorizing the data and dividing them into parts based on some criteria. We can easily get some useful information from each partition. For example, if we partition the record of students who appeared in the test based on gender, we can easily find the top scorer from both genders the least scored marks from both genders, and in fact, we can get the marks at any position. The Nth-value function performs this for us. Let’s see how can we get the first, last, and nth values of a partition in PostgreSQL.
How to Get the First, Last, and Nth Value of a Partition in Postgres?
We can get any value from a partition using the nth value function. We can write the basic syntax for this function like this:
NTH_VALUE ( Expression, Offset ) OVER ( [PARTITION BY partition_expression, ... ] ORDER BY sorting_expression [ASC | DESC], ... )
In the above syntax:
● The NTH_VALUE() FUNCTION takes in two arguments.
● The “Expression” is the expression we want to apply the NTH_VALUE function.
● Offset depicts the number of rows in one window relative to the first row. It is basically an integer.
● PARTITION BY clause divides the data values into partitions.
Let's consider an example to apply the concepts on so that it brings more clarity.
Example: How to Get the First, Last, and Nth Value of a Partition in Postgres
Let’s consider the table named “test_scores” containing the candidate data and marks records of all the candidates who appeared in the test. The table looks like this:
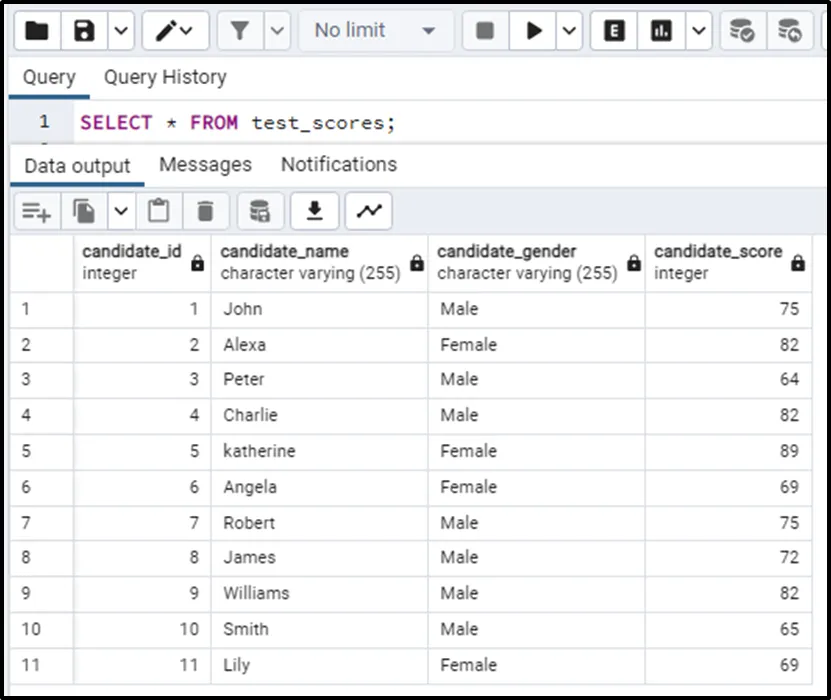
Now let’s move toward finding the first value of a partition.
Example 1: How to Get the First Value of a Partition in PostgreSQL
Will can get the first value of a partition from table “test_scores” using the above example.
The query for this case can be written as:
SELECT *, FIRST_VALUE (candidate_score) OVER ( PARTITION BY candidate_gender -- we will partition on the base of gender ORDER BY candidate_score DESC -- The ordering will take place based on scores ) AS top_scores FROM test_scores;
In the above syntax:
● After the PARTITION BY, we have specified the name of the column on the base of which we want to partition the data. It is candidate_gender in this case.
● We have sorted our score data in descending order.
● The FIRST_VALUE() function takes an argument as candidate_scores, this means that we will get the first value from the candidate_score column.
So what this code does is, We have applied the FIRST_VALUE() function on the candidate_score so the first value will be returned. It arranges the candidate_score in descending order that is the top scores are arranged in the table first. Now the partition is done based on gender so there will be two partitions male and female. Now the FIRST_VALUE() function will simply give the 1st value of every partition.
The above code will give the top scorers from both of the partitions i.e. genders. The output looks like this:
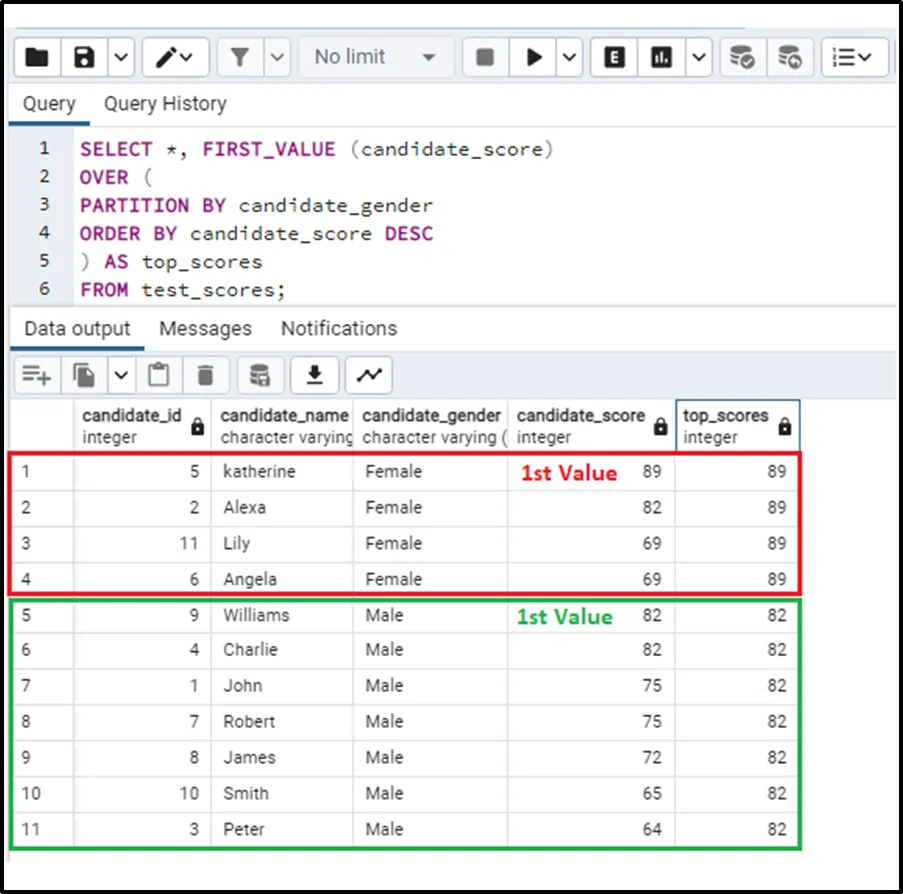
You can see that the new column, top_scores gives the first value i.e. the top scores for both the gender categories.
So this is how we can find the first value of any partitions.
Example 2: How to Get the Last Value of a Partition in PostgreSQL
We can similarly get the last value of a partition in PostgreSQL. The specific function used for it is the LAST_VALUE function. Let’s take the exact example as we did above and find the last value for the partitions. The query can be written as:
SELECT *, LAST_VALUE (candidate_score) OVER ( PARTITION BY candidate_gender ORDER BY candidate_score DESC RANGE BETWEEN -- A description of this constraint is provided below UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS lowest_marks FROM test_scores;
This syntax is almost the same as previous one, just there is one change i.e.:
“RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING” This statement is made up of two-row clauses. The purpose of the row clauses is to specify the window frame relative to the current row. The UNBOUNDED PRECEDING gives all rows that are present before this/current row and the UNBOUNDED FOLLOWING means all rows that are present after this/current row. We have defined our window range this way.
The output of the above query is:
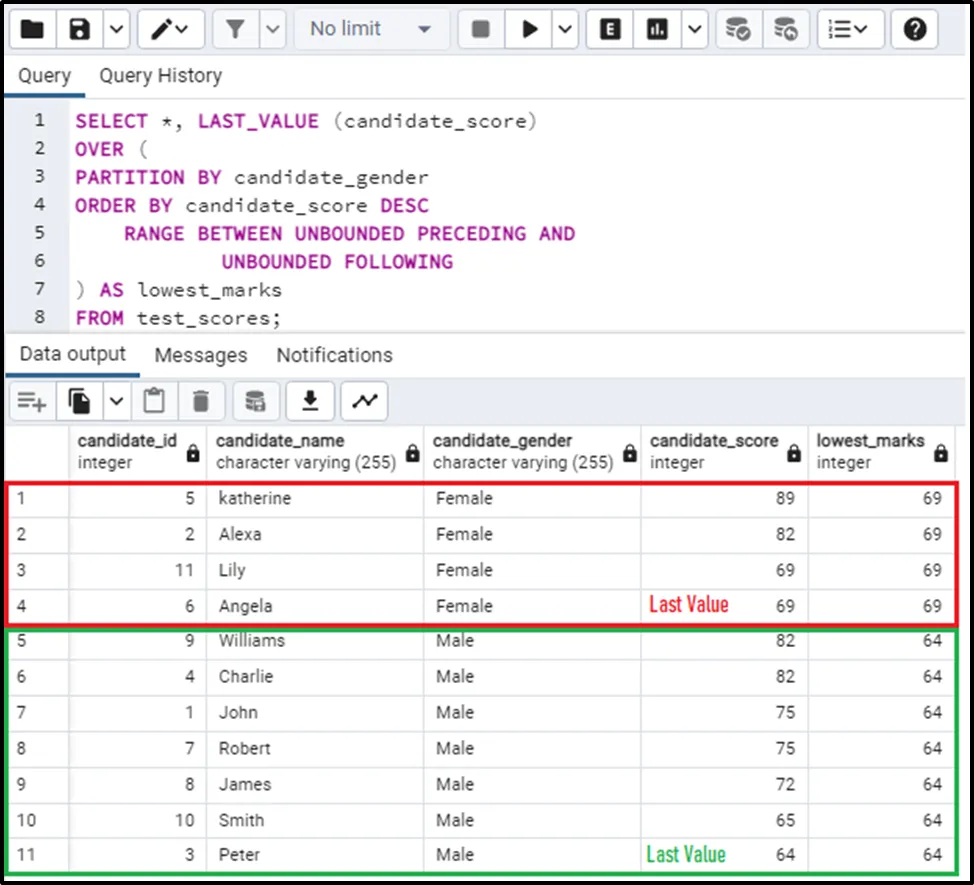
The query has returned the last value for each partition. The last value gives the lowest marks from each partition.
Using the same approach, the last value from a partition can be found. Any nth value can also be found similarly. Let’s see how.
Example 3: How to Get the nth Value of a Partition in PostgreSQL
We can get the nth value for partitions in a similar way. We will need to set and specify the offset as well. The offset will be an integer representing the n. For instance, to get the 3rd value, we will specify the offset as 3.
Let’s see how to query this.
SELECT *, NTH_VALUE (candidate_score,3) OVER ( PARTITION BY candidate_gender ORDER BY candidate_score DESC RANGE BETWEEN UNBOUNDED PRECEDING AND -- description of this constraint is provided above UNBOUNDED FOLLOWING ) AS third_position FROM test_scores;
The query is the same as in the above cases additionally we have specified the offset as 3.
The output of this query will give the 3rd value for both of the partitions. The output looks like this:
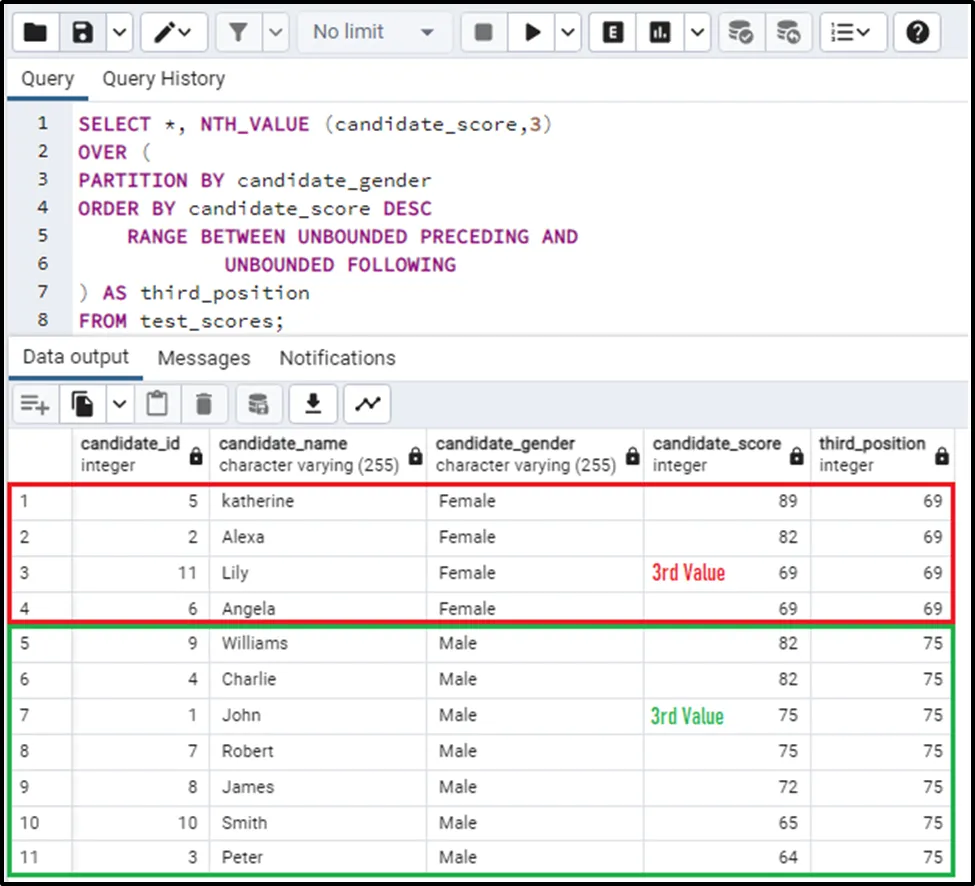
So this is how all the functions work.
Conclusion
We can get the first, last, and any nth value from each partition. The FIRST_VALUE() function takes in the column name from where we will get the first value similarly in the LAST_VALUE() function. The NTH_VALUE() function takes 2 arguments the first is the column name from which we want to get the nth specified function and the second argument is the offset that specifies the value we want to get. In this article, we have discussed how to get the first, last, and nth values from each partition in detail with practical examples.

