
Finding and deleting duplicate records is a frequently performed task while working with databases. To find duplicates, an aggregate function named COUNT() is used in Postgres. At the same time, Postgres offers various methods for deleting duplicate records. One such method is the “DELETE USING” statement.
This post demonstrates removing duplicate records in Postgres using the “DELETE USING” statement.
How to Drop Duplicates Using Postgres DELETE USING Statement?
Let’s learn how to find and remove duplicates in Postgres:
Finding Duplicates
The following syntax shows how to find duplicates in Postgres via the COUNT() function:
SELECT col_name, COUNT(col_name) FROM tab_name GROUP BY col_name HAVING COUNT(col_name)> 1;
The above query will count if the selected column has some duplicates or not.
Removing Duplicates
To remove duplicates from a Postgres table, you need to use the following syntax:
DELETE FROM tab_name row_1 USING tab_name row_2 WHERE condition;
Let’s put these concepts into practice for a profound understanding.
Sample Table
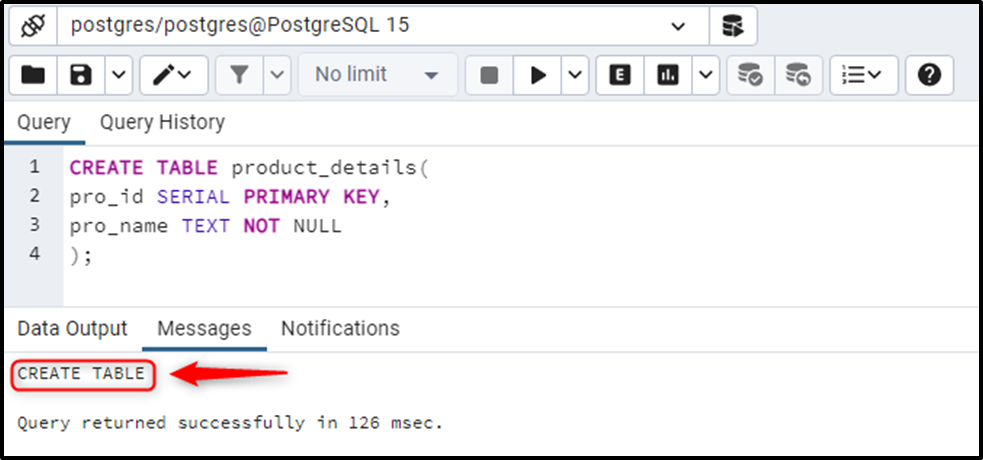
Execute the below-provided statement to create a sample table named “product_details”:
CREATE TABLE product_details( pro_id SERIAL PRIMARY KEY, pro_name TEXT NOT NULL );
Now use the INSERT INTO statement to insert the product’s info into the product_details table:
INSERT INTO product_details(pro_name)
VALUES('Laptops'),
('Chargers'),
('Tablets'),
('Personal Computers'),
('Laptops'),
('Chargers'),
('Tablets'),
('Random Access Memory (RAM)'),
('Hard drive'),
('Laptops'),
('Chargers'),
('Tablets'),
('Laptops'),
('Chargers');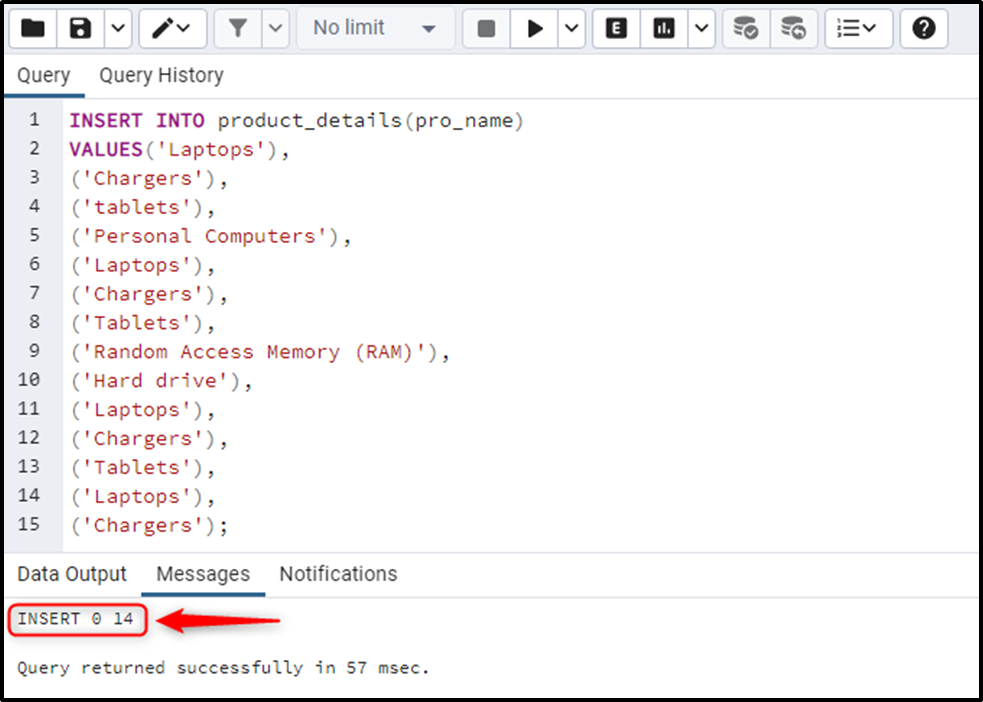
Now use the “SELECT *” command to query/fetch the data from the “product_details” table:
SELECT * FROM product_details;
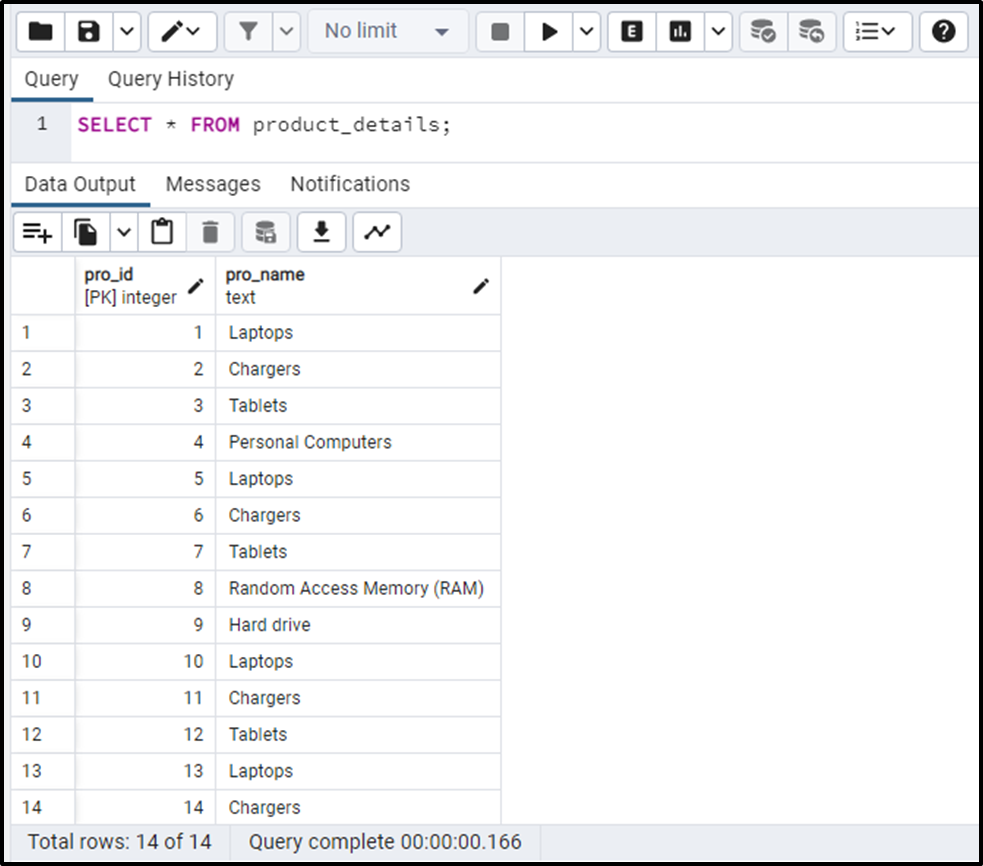
The output snippet proves that the “product_details” table has various duplicates.
Example 1: Finding Duplicates Via the COUNT() Function
This example will teach you how to find the duplicates in Postgres via the COUNT() function:
SELECT pro_name, COUNT(pro_name) FROM product_details GROUP BY pro_name HAVING COUNT(pro_name)> 1;
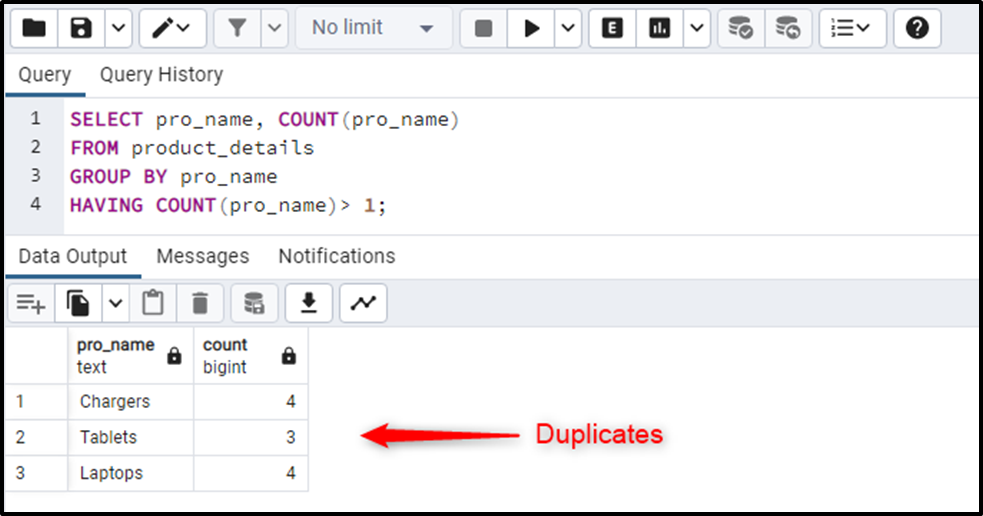
The count function retrieves all duplicate records grouped by product names.
Example 2: Removing Duplicates Via the DELETE USING Statement
To remove the duplicates from a specific table, execute the DELETE USING statement as follows:
DELETE FROM product_details pd USING product_details pd_new WHERE pd.pro_id < pd_new.pro_id AND pd.pro_name = pd_new.pro_name;
Let’s comprehend the above query stepwise:
- Specify the targeted table in the DELETE statement, for instance, “product_details”.
- The USING clause is used to join the product_details table with itself.
- Next, the WHERE clause is used to check if two different rows(pd.pro_id <pd_new.pro_id) have the same product name.
This way, all those records will be deleted from the selected table that satisfies the criteria specified within the WHERE clause:
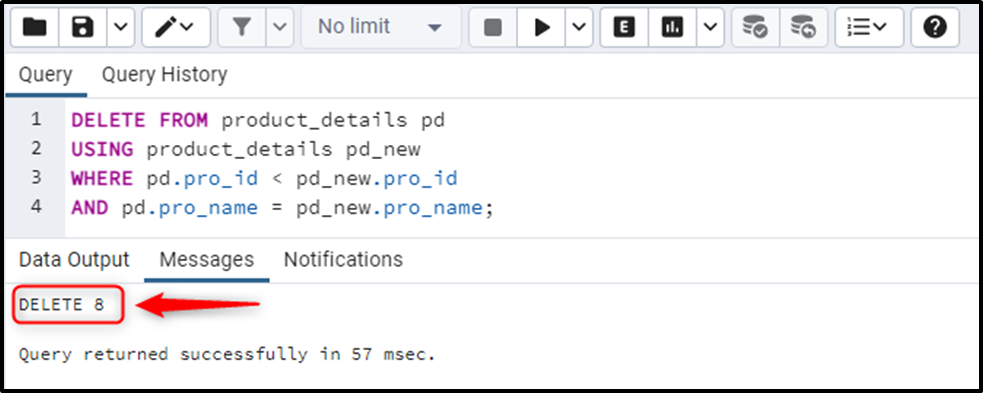
The above snippet states that eight records have been deleted from the product_details table. Let’s verify whether the product_details table still has duplicates or not:
SELECT * FROM product_details;
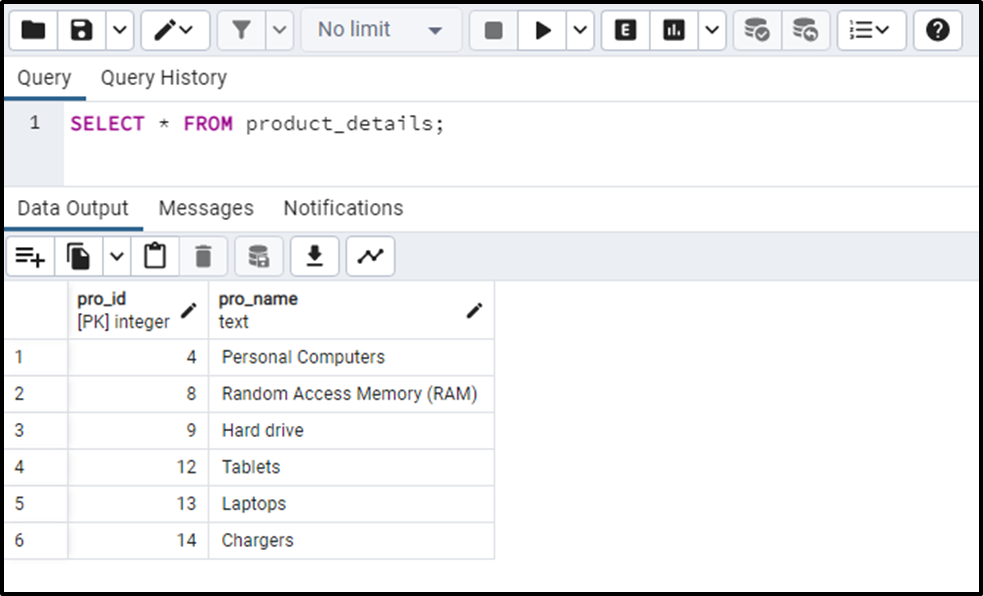
The output demonstrates that the “product_details” table has unique records only.
Conclusion
In PostgreSQL, an aggregate function named COUNT() is used to find duplicate records. While to drop the duplicate rows, the “DELETE USING” statement is used in PostgreSQL. The COUNT() function checks if the selected column has some duplicates or not. Once the duplicates are found, after that, you can use the DELETE USING statement to delete those records. This post explained how to find and remove duplicates in Postgres using practical demonstration.


