
By default, PostgreSQL supports exact searches. For Example, if we search for “mobile phone”, PostgreSQL will look for the exact same field named “mobile phone” in the database tables and will show the result accordingly.
What if a user wants to buy a shirt and a watch and he searches for “shirts and watches”? Or what if the user searches for a term with misspell? PostgreSQL generally searches for the same results as the sentence/phrase given by the user. But the major flaw in this approach is that not necessarily there would be products existing with the same name. Consequently, this will affect the system so much and will result in a reduction of sales causing a big loss for the company.
Simple Text Search
There are many operators that are used to perform basic string matching. The most commonly used are LIKE/ILIKE(SQL wildcard matches), where LIKE is case sensitive and ILIKE is case insensitive. Two other commonly used methods are SIMILAR TO(SQL Regex) and ~(POSIX Regex).
But these approaches do have some limitations which made them less ideal for use. These approaches lack linguistic support i.e. they are unable to identify synonyms of the words used, and sentence structure, and ignore the frequently occurring words. They do not possess the ability to rank the search results. These queries are also slow in nature because of the limited indexing support.
Considering the limitations of simple text search, below are some of the major requirements that need to be fulfilled for an advanced text search:
● Search should be case insensitive.
● User-entered search terms will be transformed into the query and the result should return to the user.
● Words in the query should correspond variants i.e. if a user searches for ‘shirts’ all the results having the word ‘shirt’ should also appear in the search results.
Let’s have a look at how a simple text search works:
Step 1: Create a Table and Insert Values
Let's create a database table named “search” and insert some values in it, we will write the following query:
CREATE TABLE search(documents TEXT);
INSERT INTO search(documents)
VALUES ('He eats the cake'),
('What is the date?'),
('this wil reduce the heat'),
('that one t-shirt is my favourite'),
('I am eating the food '),
('He cooks the meat'),
('I need to buy new watch'),
('we all need to treat others with respect'),
('who else eats pie?'),
('I will not wait for so long'),
('I will eat the whole box of chocolates'),
('this shirt is not mine');
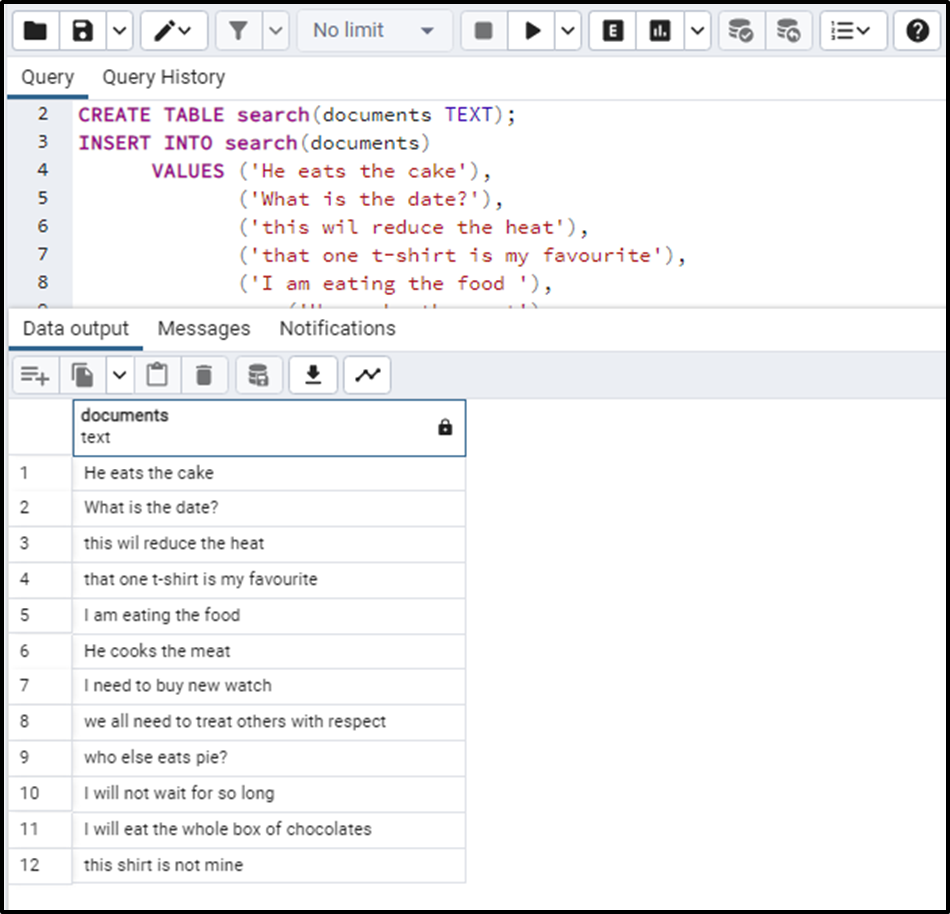
SELECT * FROM search;The above query will output the following table:
Step 2: Perform a Simple Search
Now if we perform searches with ILIKE, which does case-insensitive matching, It would find all the data(also called documents) that includes that specific term the user has searched for. It will also return the results that contain the term in the form of a sub-string. Let's apply this thing to the above example:
SELECT documents, documents ILIKE '%eat%' AS matches FROM search;
The output will be:
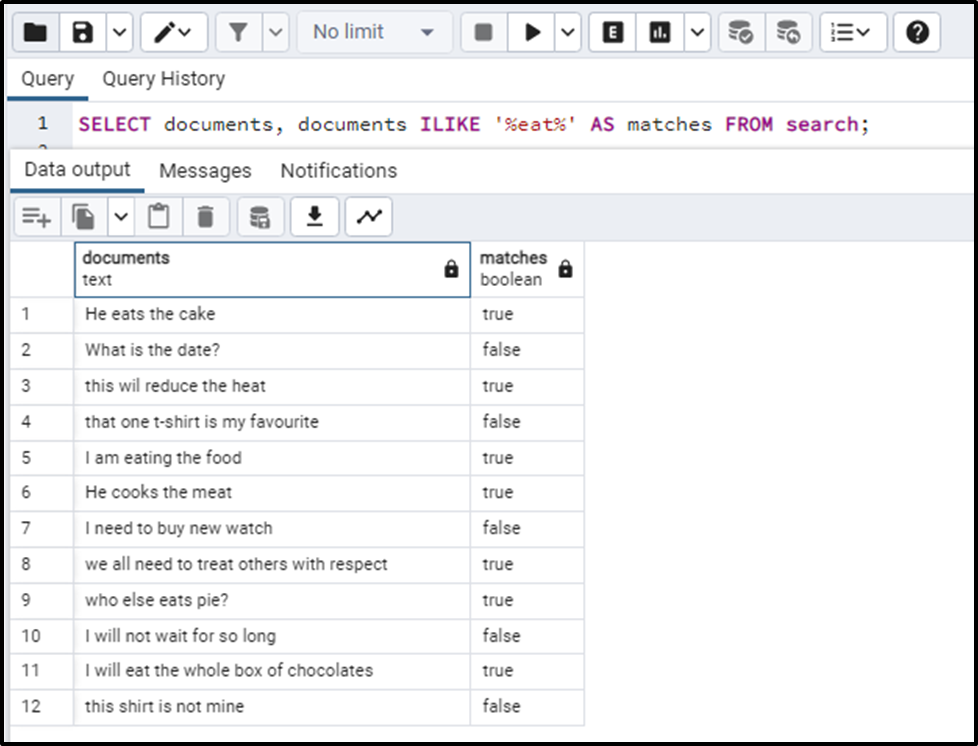
We can clearly see that ILIKE statement has found all the data that includes the term “eat”. It will also return the results that contain “eat” as a sub-string like heat, meat, treat, etc. But we know that these searches are totally irrelevant to the search results. They are just spamming the search results.
Now to fix it up, we will write another query in order to remove spam results. Following will be the query:
SELECT documents, documents ILIKE '% eat %' AS matches FROM search;
The output of the above query is:
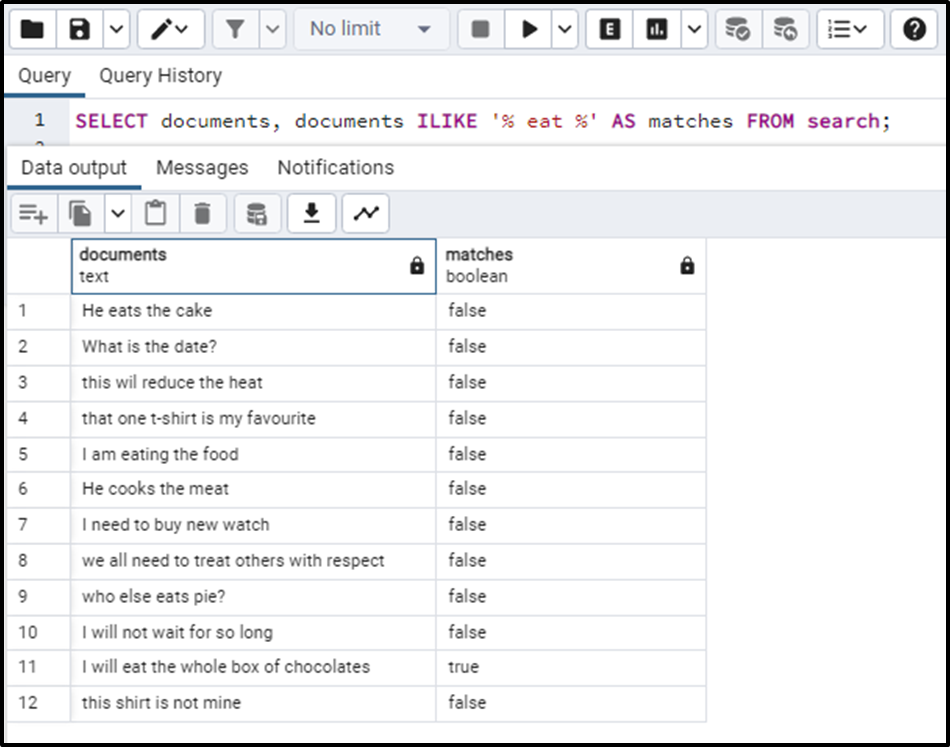
Now observe that the above query has narrowed and specified the search results so much that even the term ‘eat’ is not identified by the search(in row number 1). We can fix it by specifying all the synonyms for terms with the ILIKE statements separated by OR operators i.e.
SELECT documents, (documents ILIKE '%eat%' OR documents ILIKE '%eats%') AS matches FROM search;
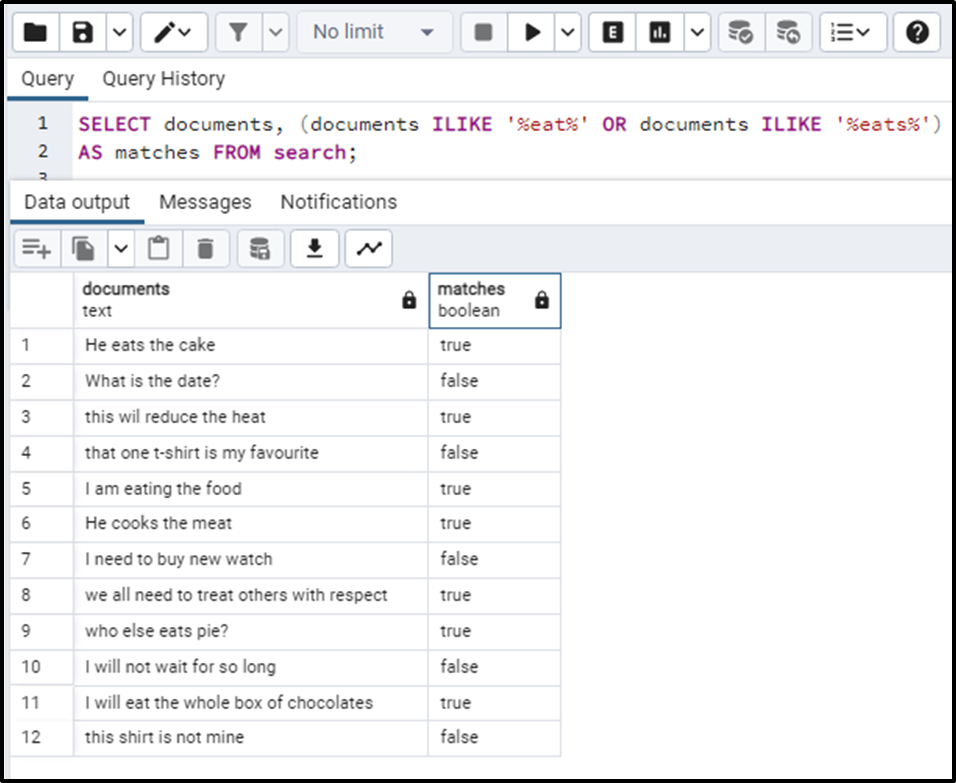
We can clearly see that this is not a good approach to be used. This will become very complex if we start to write the same thing for each and every term. Also, hard coding is never a good approach!
We have seen so many limitations of simple text search, which are to be seriously considered. In the place where ordinary search fails, the full-text search appears to help.
PostgreSQL Full-Text Search
We have seen major limitations of simple text search but we don't need to worry because full-text search is a great savior. To perform full-text search on a document you need to pass that document from different stages. Let's go over them one by one.
Step 1: Get the Document Ready
PostgreSQL does not directly apply the full-text search directly to the document, that is stored in text data type. Instead, the document needs to be converted into a more search-optimized data type called tsvector. For this specific work, the to_tsvector function is used. The basic syntax of this function is
to_tsvector([ config regconfig, ] document text) → tsvector
The to_tsvector does some processing measures on the txt of the documents. The to_tsvector first breaks the document into words. These words are then mapped to one or multiple dictionaries. Dictionaries are just a mapping of words that have been normalized. These normalized forms are referred to as lexemes. Doing this will convert words into their base words for example; happiest maps to happy and hoping maps to hope. So how it works is, if the word matches with the dictionary entry, its lexemes are added to the tsvector. The to_tsvector() function returns a tsvector list aligned with their positions in the document with other words like prepositions etc.
Let’s have a glance at how the to_tsvector works. We can write the query as
SELECT to_tsvector('We are eating the best mangoes together');The query will output the main tsvectors in the string provided to the function along with their positions in the string with respect to the preposition used like “we”, “are” and “the”. The following is the result of the previously mentioned query:
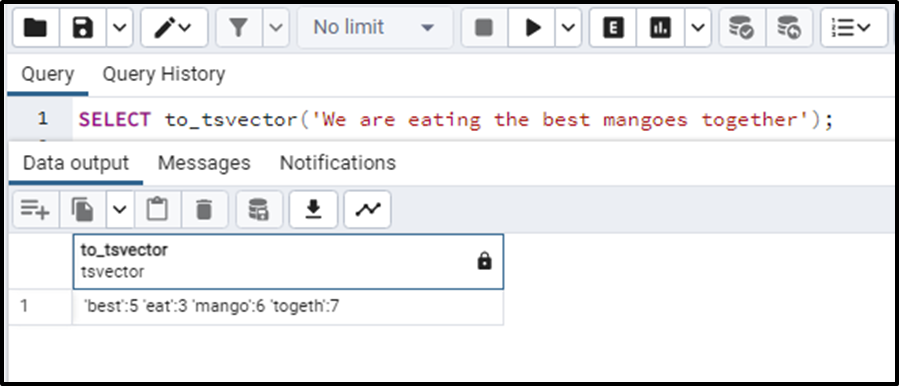
This is how the to_tsvector works.
Another function used is the “to_tsquery() function”. This function converts the keywords into normalized words/tokens. The below query demonstrates the working of the to_tsquery function:
SELECT to_tsquery('eating & best & mangoes & together');The output of this query will be all the normalized words in the above-given string. The output is:
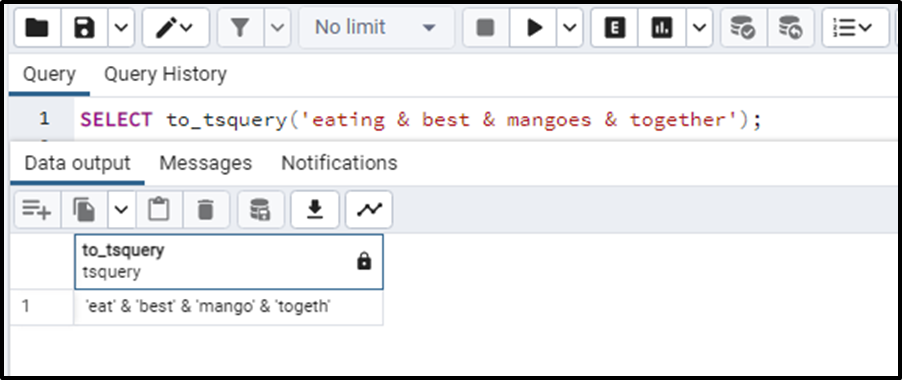
We will see how these two functions can be used together to perform the full-text search.
Step 2: Perform the Full-Text Search Function
To perform the full-text search, the to_tsvector, and the to_tsquery functions are used together along with the matching operator i.e. @@. This matching operator returns a boolean value after the execution of the word search (tsquery) against the tsvector document.
We will consider the same above-considered example to perform a full-text search on it. Let’s use the to_tsquery and to_tsvector functions to perform the full-text search. Consider the following query for this purpose.
SELECT * FROM search WHERE to_tsvector(documents) @@ to_tsquery('eat');Let’s see what the query returns. The query upon execution gives the following output:
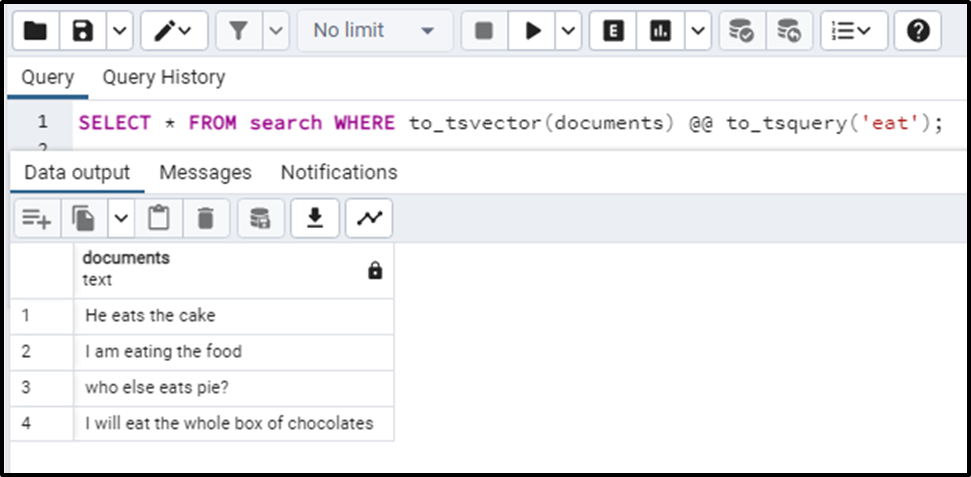
We can see that the query has returned the documents having the term eat and where the term eat is meant as eat, not used as the prefix or suffix.
This is the way we can conduct a full-text search. We can also add some other conditions for the search results by using operators such as AND and OR operators to perform the custom search.
For example, if we want to search for the term “eat” where the term “chocolate” also comes we will write the query as
SELECT * FROM search WHERE to_tsvector(documents) @@ to_tsquery('eat & chocolate');The “&” is the AND operator. So the output of the query will only be that document where the terms eat and chocolate come together.
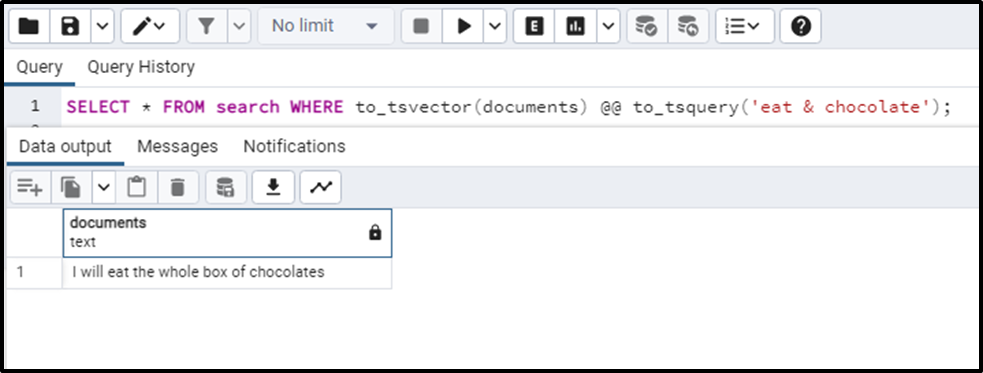
Similarly, we can add the “|” i.e. OR operator, “!” i.e. NOT EQUAL operator and the “ ” i.e. double quotation operator that returns the exactly same term you searched for. We can also combine all these operators to specify a custom query as per our wish.
This is the way we can conduct a full-text search effectively.
Conclusion
The pattern matching operators are provided by PostgreSQL to perform the search. But this search is a simple search that is done using the LIKE, and ILIKE operators. Using a simple search for the searching purpose is not a good approach so we need to perform the searching operation using the full-text search. This search returns all the possible results for the searched terms and their variants as well which was a drawback of the simple search approach. In this article, we have learned how the simple search approach works and what drawbacks this approach has while performing a search. Also, we have learned how can we use the full-text search approach for effective searching with proper implementation.


