
Customers often ask us what is the correct setting for max_connections on their PostgreSQL cluster? There is a short answer to this question, and there is a very, very long answer. The short answer is: accept the default if that works for you, or try 10 times the number of CPU cores and see if that works ok.
There is another short answer which is: you may be asking the wrong question.
The original implicit assumption is "more connections will get me more throughput". This is often false. A question usually worth pursuing is "How can my existing set of connections be used efficiently?"
If you think that your application wants more connections and you are considering raising max_connections, then you need to understand that connections carry overhead. This is a generalization: there is overhead of initializing each connection, there is overhead of maintaining an open connection, there is overhead of process concurrency in the OS, and there is overhead of concurrency in the database. Each connection corresponds to a separate operating system process and a separate TCP or Unix socket, and those things have their own hard and de facto limits in the OS as well.
Connection initiation overhead can seriously impair common kinds of web applications that make database connections for each web request. In this common scenario, each connect-query-disconnect cycle is so slow that the architect solves the problem by increasing the number of concurrent connections. As mentioned above, concurrency brings its own problems. If you have a lot of these connect-query-disconnect cycles then you can probably dramatically speed things up by using a connection pooler and forget about raising max_connections.
Demonstration of Connection Initiation Overhead
Here I share some simple benchmark results that illustrate connection initiation overhead. I did this by running a simple pgbench benchmark with and without pgbouncer, a connection pooler.
Connection poolers are another subject of frequent confusion. Contrary to frequent first impressions, connection poolers do NOT allow a greater number of concurrent connections. Instead, they manage a pool of open connections that clients take turns using. The benefit is near elimination of connection initiation overhead, and this really speeds things up.
pgbench is a simple benchmarking program that ships with PostgreSQL. I used it to initialize a benchmark database with the default options. This creates a database only 22MB in size: that means the entire database will quickly be cached in memory after a few benchmark test runs.
I configured both the pooled and direct-connected benchmark clients to both connect to PostgreSQL via TCP sockets on the localhost and I specified that it run only a single client at a time. I specified the --select-only option of pgbench, causing it to only issue SELECT statements: this eliminates disk I/O, locking, dirty cache, and vacuum from consideration. Lastly, I specified the --connect option of pgbench, which, as its documentation explains, "Establish a new connection for each transaction, rather than doing it just once per client session. This is useful to measure the connection overhead." Each benchmark simply does:
- Connect to PostgreSQL.
- Run a single SELECT query.
- Disconnect.
This cycle repeats as fast as it can for the single client process. I ran each benchmark for 60 seconds and recorded system performance metrics with sar on a five second interval. I ran pgbench three times using direct PostgreSQL connections and three times connecting via the pgbouncer connection pooler. This all ran on PostgreSQL 9.6 on my desktop system with Intel i3 cpu. The three repetitions produced very similar results but the difference between direct and pooled connections was dramatic:
Benchmark Results
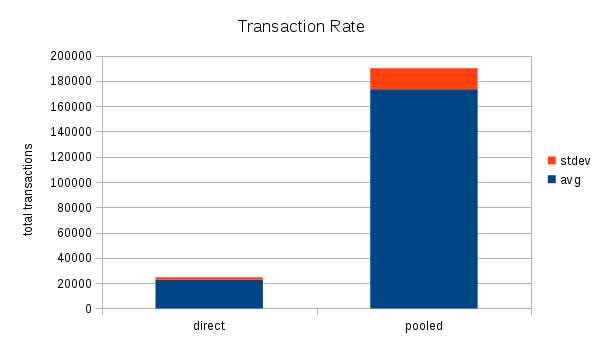
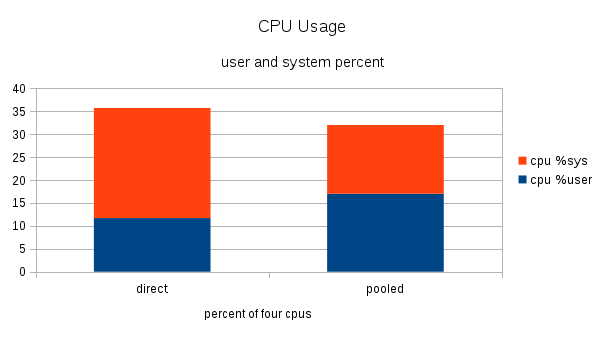
The benchmarks with connection pooling produced eight times more transactions while using less cpu time!
Yes, connection initiation carries significant overhead, and a connection pooler is the solution.