
PostgreSQL offers several window functions with different functionalities. DENSE_RANK() is one such function that assigns a unique ranking to each row of a partition without leaving any gaps in the ranking order. It assigns consecutive/sequential ranks to the rows, even if they have the same values. However, rows/records having the same values receive the equal (same) rank.
This write demonstrates how to use DENSE_RANK Function in Postgres using the following outlines:
- Applying DENSE_RANK() Function Over a Particular Table
- Applying DENSE_RANK() Function Over a Table Partitions
How to Use the DENSE_RANK() Function in PostgreSQL
To use DENSE_RANK() function in Postgres, all you need to do is follow the syntax provided below:
DENSE_RANK() OVER ( [PARTITION BY partition_col_list] [ORDER BY order_col_list] )
In the above syntax, “[PARTITION BY partition_col_list]” is an optional clause that splits the result set into partitions based on columns specified in “partition_col_list”. However, if you don't use it, the stated function will consider the entire result set as one partition and ranks all the rows together as one single partition.
Let’s set up a sample table and practically implement the DENSE_RANK() function on that table.
Sample Table
Let’s begin with creating a sample table named “student_details” that keeps the student details:
CREATE TABLE student_details( st_id INT PRIMARY KEY, st_name TEXT, st_gender CHAR, st_grade INT NOT NULL );
Once the selected table is created, insert some new records into it using the following query:
INSERT INTO student_details(st_id, st_name, st_gender, st_grade) VALUES (1, 'Alexa', 'F', 1), (2, 'Joseph', 'M', 1), (3, 'Daniel', 'M', 2), (4, 'Anna', 'F', 1), (5, 'Stephan', 'M', 2), (6, 'Alex', 'M', 3), (7, 'Stephenie', 'F', 3), (8, 'Clarke', 'M', 3), (9, 'Natalia', 'F', 2), (10, 'Joe', 'M', 2);
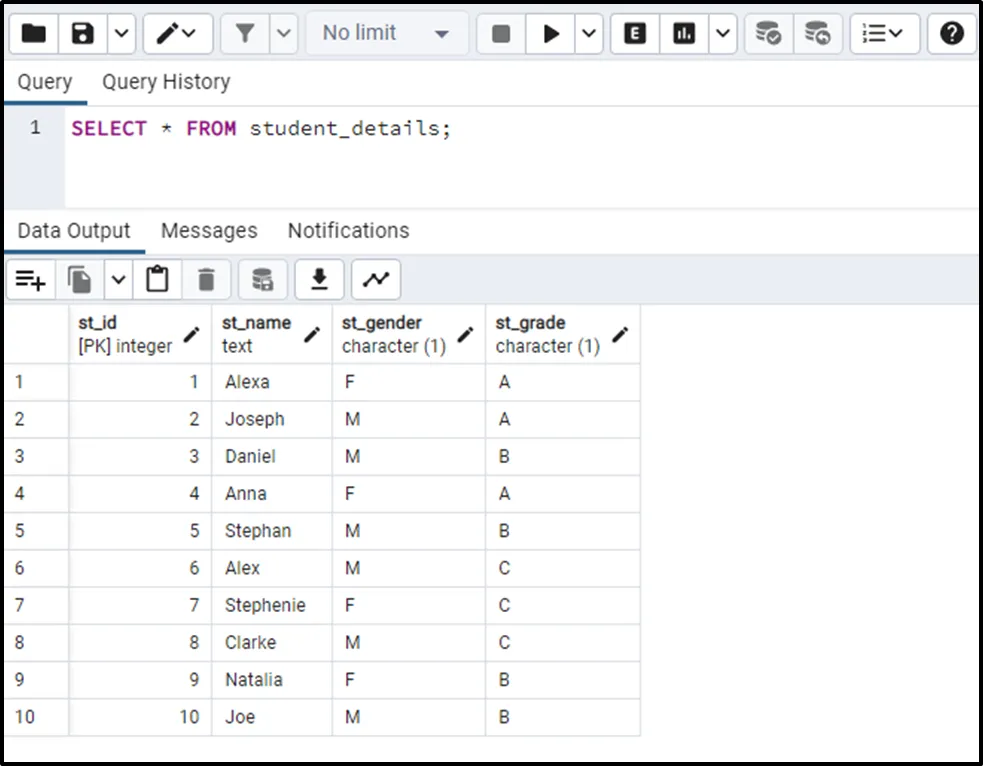
Let’s fetch the “student_details” table to confirm the inserted data:
SELECT * FROM student_details;
Example 1: Applying DENSE_RANK() Function Over Entire Table
In this example, we will apply the DENSE_RANK() function on the “student_details” table:
SELECT *, DENSE_RANK() OVER ( ORDER BY st_grade ) AS dense_rank FROM student_details;
In the above code:
- The PARTITION BY Clause is skipped, so the DENSE_RANK() function will consider the entire table as one partition.
- Each partition will be sorted in default (ascending) order based on the “st_grade” column.
- The DENSE_RANK() function will assign the rank to each row/record based on the st_grade column:
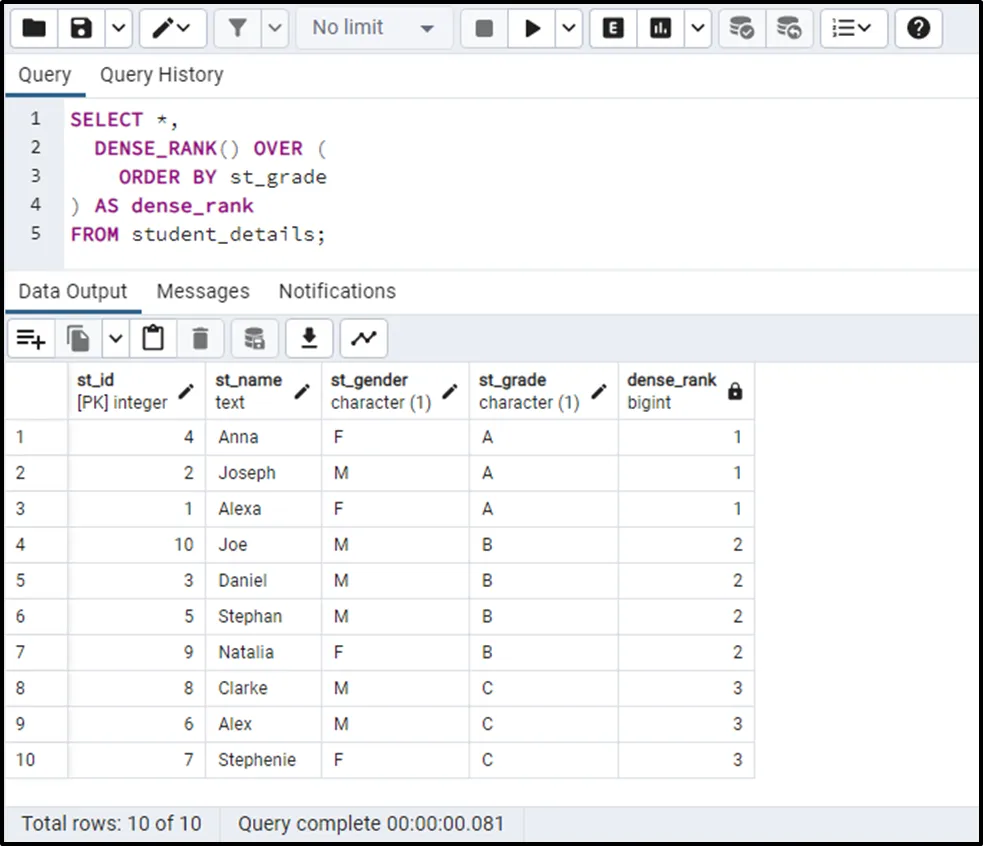
The output demonstrates that the same rank is assigned to the students having the same grade.
Example 2: Applying DENSE_RANK() Function Over Table Partitions
In this example, we will apply the DENSE_RANK() function on the table’s partition instead of the entire result set:
SELECT *, DENSE_RANK() OVER ( PARTITION BY st_gender ORDER BY st_grade ) AS dense_rank FROM student_details;
In the above code:
- Partitions are created based on the “st_gender” column.
- Each partition will be sorted based on the “st_grade” column.
- The DENSE_RANK() function will retrieve the rank of each row/record within its associated partition:
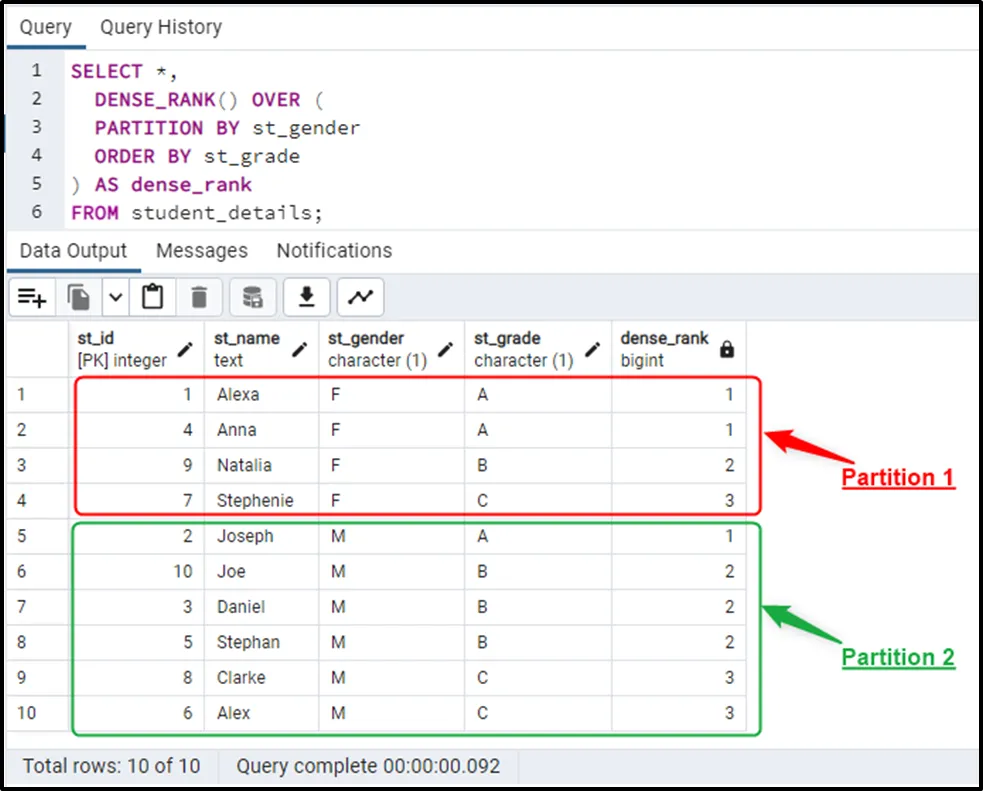
The output demonstrates that the ranking restarts from 1 for the new partition.
Conclusion
The DENSE_RANK() function assigns a rank to each row of a partition based on the specified sorting order. It starts ranking from 1 for the first row and increases the rank for each subsequent row. However, rows with identical values will have the same rank. Moreover, when the stated function meets a different partition, the ranking restarts from 1 for that new partition. This write-up has demonstrated various use cases of the DENSE_RANK() function.

